







Preparare un immagine per il riconoscimento e categorizzazione tramite Ai
Quanto sarebbe divertente collegare una videocamera ad un arduino, e registrare una partita a poker, a dama, a scacchi…
Si potrebbe creare un arbitro computerizzato, sfruttando anche il Text-To-Speech per segnalare verbalmente i bari, creare un ai che calcola la mossa migliore e ti segnala quando la hai scelta, o fa un suono triste quando sbagli grossolanamente.
Per fare tutto questo, oltre naturalmente a creare un programma magari python (il nostro linguaggio di prima scelta) per collegarsi alla webcam e raccogliere il feed video, c’è bisogno di fare data pre-processing.
Data pre-processing
Purtroppo perché un ai sia in grado di riconoscere il campo da gioco, le carte e tutto il resto, non è sufficiente analizzare il feed video puro, bisogna togliere tutto ciò che rappresenta dati inutili, o che potrebbero facilmente confondere il nostro algoritmo.
“Garbage in, garbage out”
Con dati sporchi, ricchi di errori, si ottengono risultati sporchi e ricchi di errori
Ecco che entra in azione il data pre-processing, ovvero una procedura di filtraggio intenta proprio ad ottenere questi risultati.
Image filtering con python
Prendiamo come esempio un immagine ottenuta da un ipotetica telecamera posta sopra ad una scacchiera e i pezzi per la dama.

(Scacchiera venduta dal negozio spagnolo www.brindesvisao.com.br, link non sponsorizzato)
Supponiamo di dover far riconoscere all’ai le caselle e le dame di entrambi i giocatori, per farlo bisogna usare l’image recognition IR, però se guardate attentamente, ci sono tre diversi problemi che potrebbero confondere un ipotetico algoritmo:

le ombre che l’illuminazione traccia sul campo confondono in parte le caselle

le pedine sia bianche ma soprattutto rosse non sono esattamente dello stesso colore e sulla superfice presentano granulosità

la videocamera non visualizza le pedine tutte dalla stessa angolazione

Due dei problemi che potremmo avere sono risolvibili filtrando l’immagine, però le ombre purtroppo essendo scure e essendo spesso tracciate su caselle nere, rimarranno un problema, anche se in misura minore, che potremo però aggirare in un altro modo.
L’obbiettivo
Dobbiamo fondamentalmente rendere le superfici della dame perfettamente regolari, in questo modo potremmo riconoscerle semplicemente dando in pasto all’algoritmo di IR due cerchi, uno rosso e uno bianco, ed esso escluderà automaticamente le parti inclinate che ci davano fastidio.
Il codice
Partiamo dalle dipendenze di questo progetto:
from PIL import Image
import numpy as np
import timeSia numpy e pil si possono installare lanciando pip3 install PIL e pip3 install numpy da terminale.
Per quanto riguarda time, non solo si tratta di una libreria già presente nell’installazione base di python3, ma è anche facoltativa, in quanto la useremo solamente per calcolare l’efficienza del nostro algoritmo.
Passiamo all’apertura della nostra foto:
image = Image.open("photo.jpg")
img_data = np.array(image)
h, w, t = img_data.shapeOra la nostra immagine è salvata dentro image, i suoi dati in formato di array di numpy sono salvati dentro img_data, la altezza è h, la larghezza è w e il numero di componenti del singolo punto (3 con immagini RGB, 4 con immagini RGBA), sono salvati in t.
Possiamo fare un po’ di debug aggiungendo un print:
print(h, w, t)Che ci restituirà in output:
>> 913 866, 3Ottimo, quindi la nostra immagine è alta 913, larga 866 e non ha la trasparenza (si poteva già prevedere, considerando che si tratta di un jpg).
Ora prepariamo un nuovo array di numpy vuoto, pronto a raccogliere i pixel dell’immagine rielaborata.
new_img_data = np.zeros((h, w, t), dtype=np.uint8)Quindi creiamo un iterazione in cui eseguiamo un ciclo per ogni pixel all’interno dell’immagine. Raccogliamo intanto la lista dei tre valori (R, G, B) che formano il pixel.
for x in range(w):
for y in range(h):
r_pixel = img_data[y][x][0]
g_pixel = img_data[y][x][1]
b_pixel = img_data[y][x][2]Ora supponendo che non sia possibile posizionare perfettamente la videocamera, potrebbe essere necessario effettuare uno zoom sul soggetto, imponiamo dunque una regola che ci permetta di analizzare solo le zone interessanti.
if x in range(0, w) and y in range(0, h):Per ora abbiamo inserito w e h come estremità del range per includere tutta l’immagine, se serve per esempio tagliare i bordi a sinistra e a destra di 200px basterebbe sostituire il primo range con range(200, w-200).
Siamo arrivati al filtro vero e proprio. Per la nostra immagine abbiamo trovato che per regolarizzare abbastanza i colori si può eseguire un’operazione di questo genere,
r = (255, 0)[r_pixel < 100]
g = (255, 0)[g_pixel < 100]
b = (255, 0)[b_pixel < 100]
new_img_data[y][x] = [r, g, b]In sostanza salviamo 255 ovvero intensità massima per ogni colore, solo se il colore stesso parte da un intensità non troppo elevata.
Il programma completo, con l’aggiunta del caso in cui siamo fuori dal range interessante e la produzione effettiva dell’immagine risulta così.
from PIL import Image
import numpy as np
import time
image = Image.open("photo.jpg")
img_data = np.array(image)
h, w, t = img_data.shape
print(h, w, t)
new_img_data = np.zeros((h, w, t), dtype=np.uint8)
for x in range(w):
for y in range(h):
r_pixel = img_data[y][x][0]
g_pixel = img_data[y][x][1]
b_pixel = img_data[y][x][2]
if x in range(0, w) and y in range(0, h):
r = (255, 0)[r_pixel < 100]
g = (255, 0)[g_pixel < 100]
b = (255, 0)[b_pixel < 100]
new_img_data[y][x] = [r, g, b]
else: #siamo fuori dal range
new_img_data[y][x] = [255, 255, 255] # pixel bianco
print("Process time: " + str(time.process_time()) + "s")
new_img = Image.fromarray(new_img_data, 'RGB')
new_img.show() # visualizza l'immagine a video
new_img.save("new_photo.jpg") #salva la nuova immagine
Che produce questo risultato:
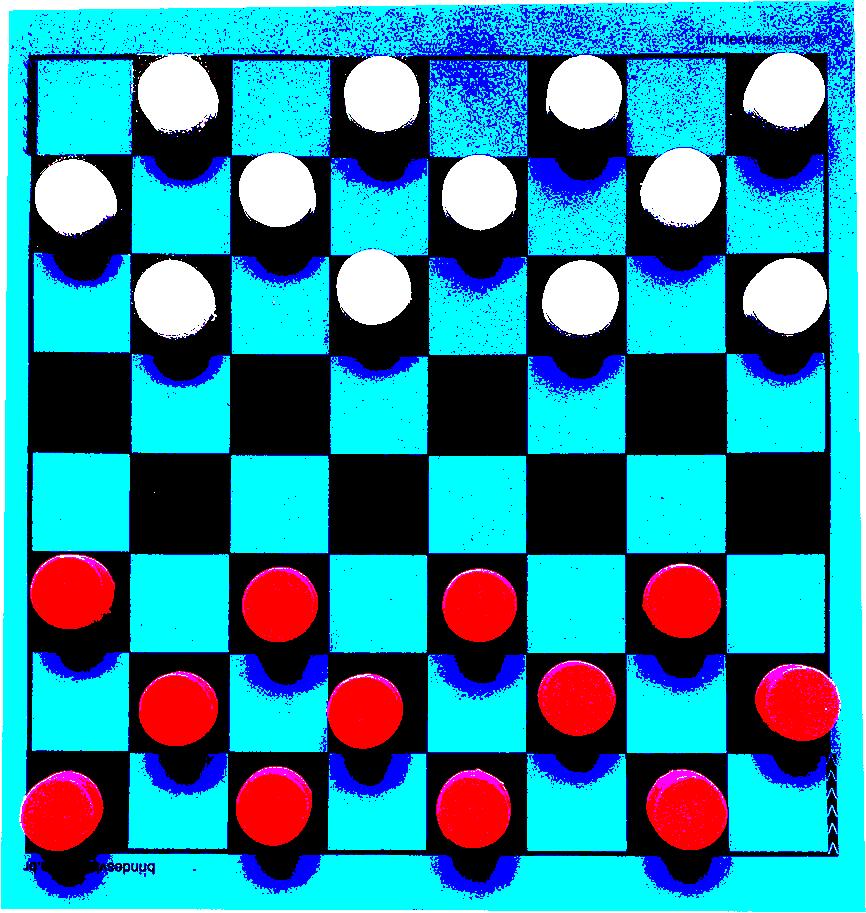
Perfetto, adesso come preventivato con dei semplici cerchi rossi e bianchi possiamo riconoscere tutte le pedine.
E la scacchiera? La scacchiera in realtà non serve, una volta riconosciuta la pedina nella relativa posizione, basta controllare in che range di pixel rientra, per capire in che casella risiede.
Ancora non soddisfatti? Si può ottenere un immagine con ancora meno disturbo effettivamente, togliere completamente ombre e scacchiera, e tenere solo le pedine, quello che davvero ci interessa.
Per farlo è sufficiente modificare il filtro:
r = (255, 0)[r_pixel > 207]
g = (255, 0)[g_pixel > 207]
b = (255, 0)[b_pixel > 207]Per ottenere il seguente risultato.

Ora è impossibile che l’algoritmo si confonda. Direste mai che questa foto è stata scattata ad una scacchiera di dama?
Avete notato un trend? Meno l’immagine è riconoscibile dall’umano, più è riconoscibile dalla macchina. Questo perché noi siamo in grado di dare molteplici significati con relativamente alta precisione, mentre una macchina non è in grado (ancora) di analizzare più di un dettaglio su un immagine senza applicare nessun filtro. Se si vogliono analizzare le ombre bisogna togliere tutto il resto, se si vuole capire quanti tasselli ha un puzzle bisogna togliere i colori, e così via. Dopo molti filtri e diverse analisi si ottiene il risultato che un umano in genere ricava con un solo sguardo.
Leonardo Bonadimani – Whatar – Filosoft