When developing even the simplest AI that implements sensors and real-world movement, simulating the algorithm inside a virtual 3d world can cut unnecessary costs and speed-up production phases.
Now, why build a 3d engine when there already are incredibly powerful options out there available for free?
Unreal Engine 5 is one of the most anticipated pieces of software in a while, it should bring big performance optimizations on the table in comparison to the previous version, and both Nanite and Lumen, the two main features, seems really promising in terms of what they will allow developers to do.
Innovation aside, there is a big issue that should be addressed as soon as possible by Epic Games, the documentation for Unreal Engine 4 is imprecise and lacking, some of the functions and blueprint nodes are even descripted in the documentation only by their name!
Unreal Engine 5 is currently available on early access, you can imagine that the documentation is simply… not there yet. In the official section of the Epic website https://docs.unrealengine.com/5.0/en-US/ we can see that as of today, there are only 12 pages of docs, describing the main changes.
We would really like to see more from Epic, UE5 should be a big turn also in terms of documentation.
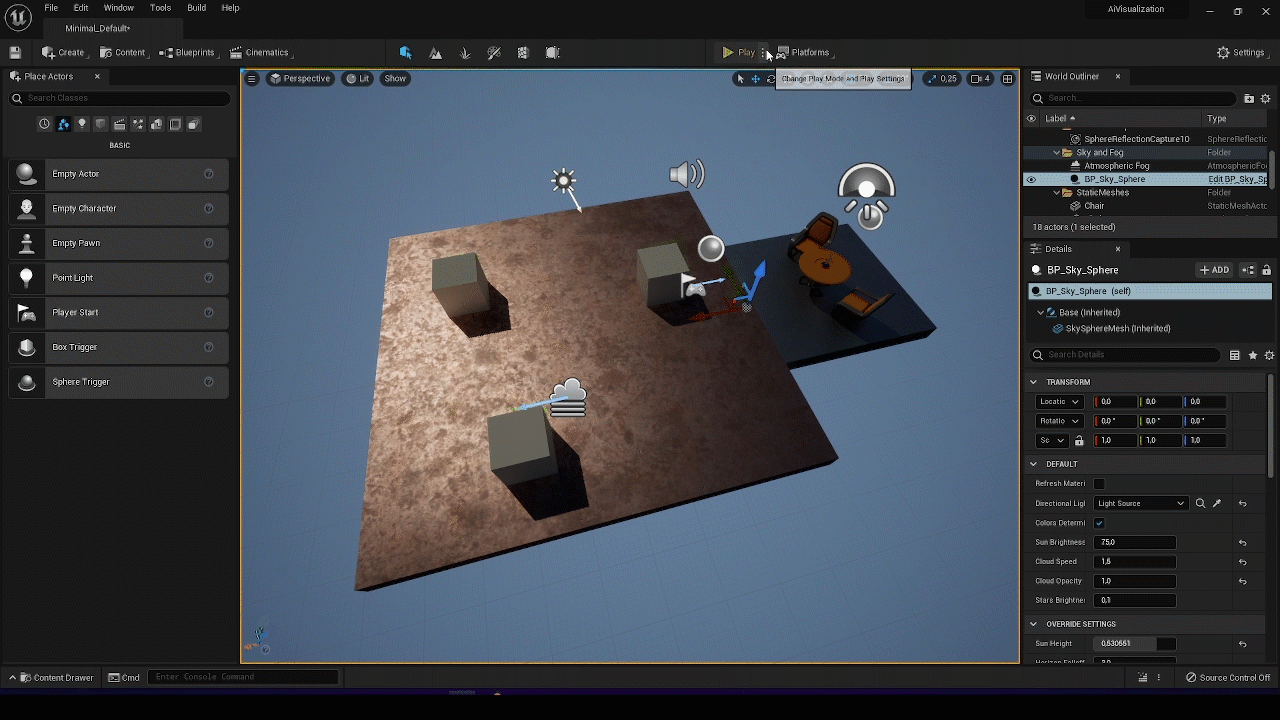
Anyway, today we are going to give you a hint on how to adapt one of the first official UE4 tutorial to the new engine version, embedding an overly simplified C++ AI into a basic Pawn (an actor with the ability to move and in the environment and be controlled by a GameController).
Inside the editor, this is what should be visible:
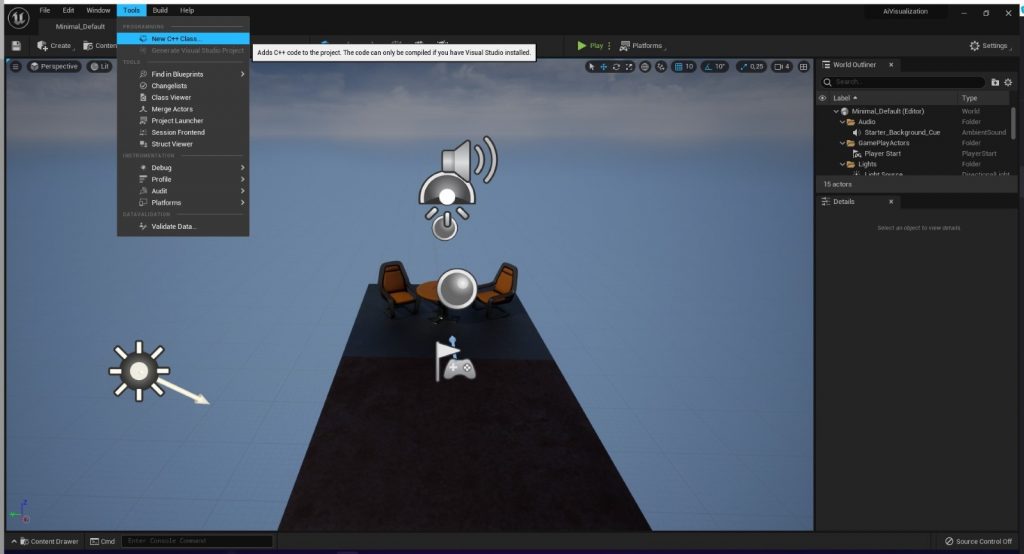
The option to create a new C++ class has been moved, now it’s under
Tools -> New C++ Class
We need to create and Pawn, let’s select that option.
If UE5 prompts you to open the log because “an error occurred”, you will probably find inside it a request for a specific .NET version, in our case it was .NET 3.1, this requirement changes on the base of the UE and VS versions. We were able to meet the requirement installing the following package: https://dotnet.microsoft.com/download/dotnet/3.1
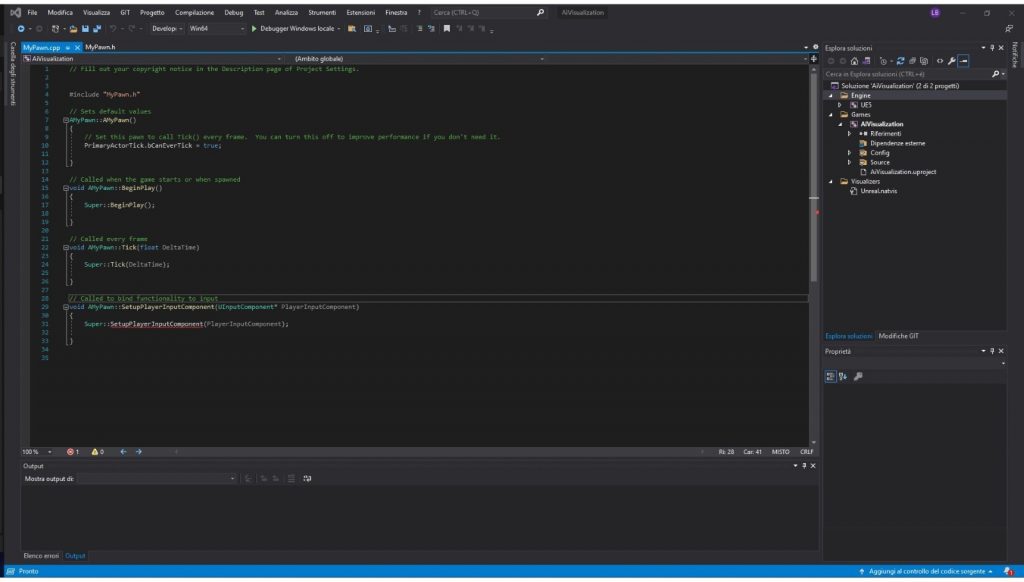
After Visual Studio takes its time to load, this is the basic script:
Adding
public:
// Sets default values for this pawn's properties
AMyPawn();
UPROPERTY(VisibleAnywhere)
UStaticMeshComponent* VisualMesh;
To the MyPawn.h (the header) under the “public” label, will add a StaticMesh componet to the actor, allowing us to edit his visual appareance.
Setting the constructer AMyPawn:AMyPawn in MyPawn.cpp:
AMyPawn::AMyPawn()
{
// Set this pawn to call Tick() every frame. You can turn this off to improve performance if you don't need it.
PrimaryActorTick.bCanEverTick = true;
VisualMesh = CreateDefaultSubobject<UStaticMeshComponent>(TEXT("Mesh"));
VisualMesh->SetupAttachment(RootComponent);
static ConstructorHelpers::FObjectFinder<UStaticMesh> CubeVisualAsset(TEXT("/Game/StarterContent/Shapes/Shape_Cube.Shape_Cube"));
if (CubeVisualAsset.Succeeded())
{
VisualMesh->SetStaticMesh(CubeVisualAsset.Object);
VisualMesh->SetRelativeLocation(FVector(0.0f, 0.0f, 0.0f));
}
}
Will set a cube as the default static mesh of the class.
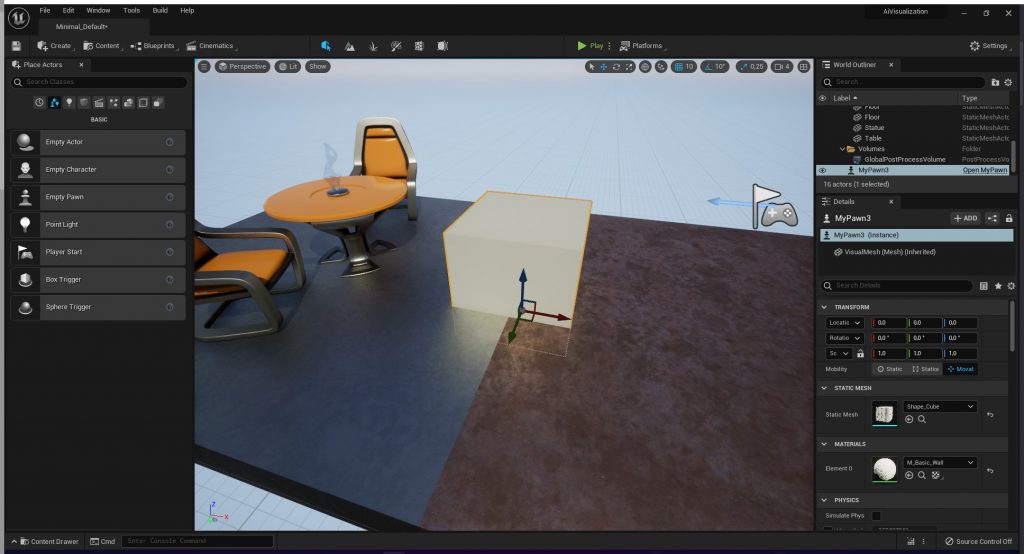
Building the project, reloading the Unreal Engine project and placing the new actor in the world from the content manager leads to this situation:
Our objective is to visually test a simple AI concept that we have previously designed, for this article lets imagine we have thought of testing a concept of aggregation.
Something like this:
-> Get all similar agents
-> Get closest agent
-> Get closer
With UE5 we can test this concept.
All we need is to edit the AMyPawn:BeginPlay() function.
Getting all the similar agents:
void AMyPawn::BeginPlay()
{
Super::BeginPlay();
TArray<AMyPawn*> Actors;
FindAllActors(GetWorld(), Actors);
for (int i = 0; i < Actors.Num(); i++) {
GEngine->AddOnScreenDebugMessage(-1, 15.0f, FColor::Red, TCHAR_TO_ANSI(*Actors[i]->GetName()));
}
}
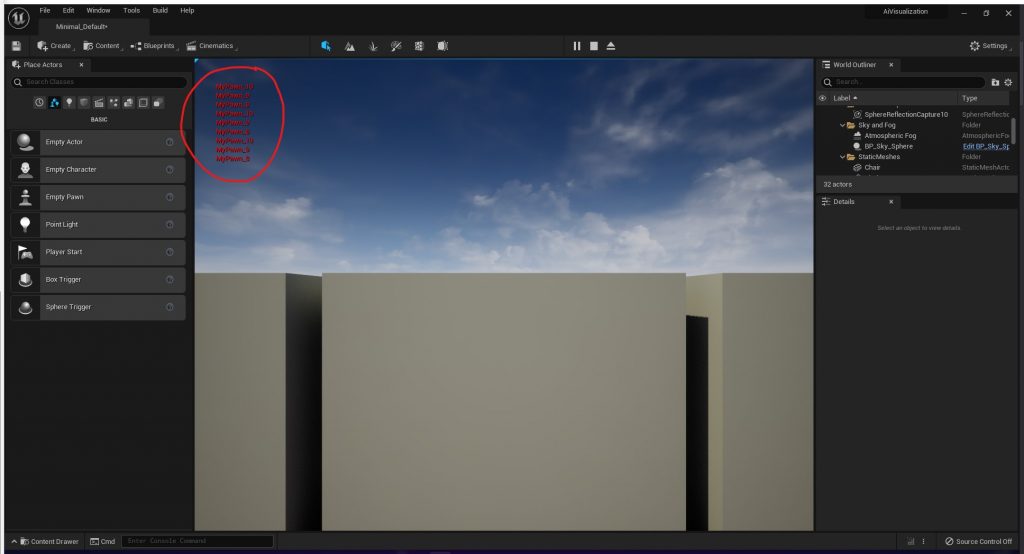
Now if we build the project and start the game, we get the log of all the MyPawn instances present in the game, keep in mind that every instance repeats this operation so if we place 3 instances, we get 9 logs:
Onto the “Get closest agent task”, modifying the current loop we can save the closest actor:
La differenziazione principale tra i vari modelli sussiste nell’esistenza di intelligenze artificiali in grado di imparare dagli eventi e dalle situazioni, o più spesso da un test-set preciso, e AI statiche, fatte e finite, che possono operare solo in un ambiente specifico, che anche se sono in grado di reagire a situazioni disparate, non hanno bisogno di essere allenate.
In questo articolo ci si riferirà talvolta agli “agenti”, ovvero costrutti software di intelligenza artificiale con un obbiettivo specifico.
Algoritmi di AI euristiche, alberi decisionali
Direct Heuristic Search
Questa categoria raggruppa genericamente tutte quelle AI che data una serie di informazioni sul target, lo stato attuale e le strategie utilizzabili, cercano una soluzione sub-ottimale spesso con una logica greedy (analisi di ogni possibilità), oppure con qualche filtro e ottimizzazione. Sono facili da sviluppare e in genere performanti, ma non hanno possibilità di confronto con algoritmi molto più precisi e avanzati come i Tree Search o le reti neurali.
Tree Search Algorithms
fonte: wikipedia.org CC4.0
Forse l’algoritmo più famoso in questa categoria è il MTTS (Monte Carlo tree search), questi algoritmi si occupano di decision making. Grazie a una previsione accurata dei prossimi rami dell’albero, si stabilisce quale stato futuro è il più conveniente, e si esegue la scelta che più avvicina la macchina a quello stato. Altri esempi di algoritmi di Tree Search sono Depth-first search, e Breadth-first search, che però non cercano il ramo più promettente, ma quello esatto, sono quindi più adatti in situazioni in cui la scelta migliore è una e la situazione presenta poche incognite.
Algoritmi di reti neurali, Artificial Neural Networks (ANNs)
Decisamente più complicati e costosi dal punto di vista di spazio di archiviazione, le reti neurali artificiali possono essere allenate a partire da un test-set, per poi agire in modo più performante e preciso di molti algoritmi euristici.
Supervised learning vs Unsupervised learning
Gli algoritmi di apprendimenti “Supervised” sono tutti quelli che si basano su un test-set specificato, ovvero che presenta dei valori di verità che accompagnano i test, come immagini di animali con una label (etichetta), che indica di che animale si tratta. Software basati su questa tecnica sono molto utilizzati nel campo del riconoscimento immagini e del natural language processing, ovvero l’analisi del linguaggio naturale, come il riconoscimento degli stati d’animo e delle opinioni dello scrittore.
Nella modalità di apprendimento “Unsupervised“, agli agenti viene presentato un test-set completamente non specificato, con un’assenza totale di label, dove l’AI si occupa di stabilire lei stessa le connessioni tra i vari input. Metodo in uso soprattutto nel campo della data science, quando si rende necessario scoprire eventuali densità all’interno di un dataset e evidenziare similarità (anche chiamate modelli) tra gli elementi che lo compongono.
Reinforcement learning
fonte: filosoft.it
Ricevere un compenso rende qualsiasi task più stimolante per noi umani. Lo stesso vale per le AI.
Nel reinforcement learning, gli agenti mirano a massimizzare il reward (la ricompensa), ogni azione che porta l’agente ad avvicinarsi all’obbiettivo incrementa il reward, mentre ogni azione controproducente lo decrementerà. Questa strategia di apprendimento è adatta a tutti quegli ambiti in cui non si conosce il metodo perfetto per ottenere quello che si desira. Immaginiamo di dover fare atterrare un drone automatizzato, i terreni, le condizioni atmosferiche, potrebbero cambiare, il drone stesso potrebbe essere danneggiato, non è possibile scrivere a priori una funzione di atterraggio sempre perfetta. Con il reinforcement learning si riesce ad allenare una rete neurale insegnandole come comportarsi sulla base di una ricompensa.
Il drone sta rallentando? Punteggio positivo, il drone urta qualcosa? Punteggio negativo. Drone schiantato? Bancarotta, e così via.
Ultimo appunto, cos’è il deep learning?
Da wikipedia: “The adjective “deep” in deep learning refers to the use of multiple layers in the network”.
fonte: moonbooks.org
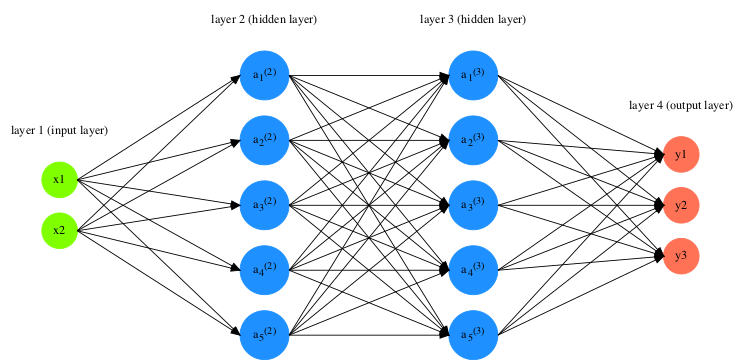
Una ANN è formata di diversi neuroni che dato un input restituiscono un determinato output. Ciò che rende un algoritmo di machine learning “deep”, è il fatto che a determinati input si assegnano determinati output che sono poi input di altri neuroni.
Lavorando nell’ambiente della produzione di contenuti mobile e web, possiamo dire con sicurezza che la risorsa a cui più ci si appoggia (dopo forse ai generatori di Lorem Ipsum per i testi di esempio), sono sicuramente le Stock Images. Sia per testare quale sia l’impatto visivo del sito o dell’applicazione che si sta sviluppando, sia talvolta proprio per abbellire il prodotto finale, è spesso necessario dover fare affidamento a dei servizi che producano queste immagini stock.
Per quanto concerne le immagini che ritraggono un ambiente naturale, il nuovissimo software basato sull’Artificial Intelligence di NVIDIA chiamato “Canvas”, sembra essere l’inizio di una rivoluzione.
Con pochissimo lavoro è possibile ottenere un immagine di un paesaggio nuovo e mai visto prima.
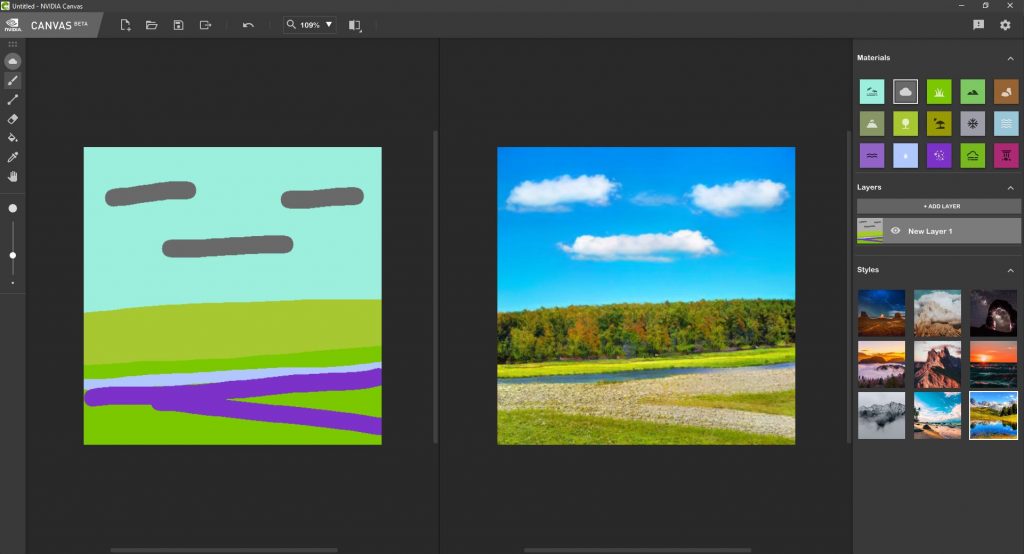
Come potete vedere dall’immagine soprastante, Canvas converte lo schizzo presente sulla parte di sinistra nell’ambiente di pianura presente sulla destra. Impressionante.
Ogni colore rappresenta una tipologia diversa di asset naturale, come in questo esempio sono presenti il cielo (azzurro), le nuvole (grigio), la foresta (verde chiaro), l’erba (verde), il fiume (azzurro), e la ghiaia (viola).
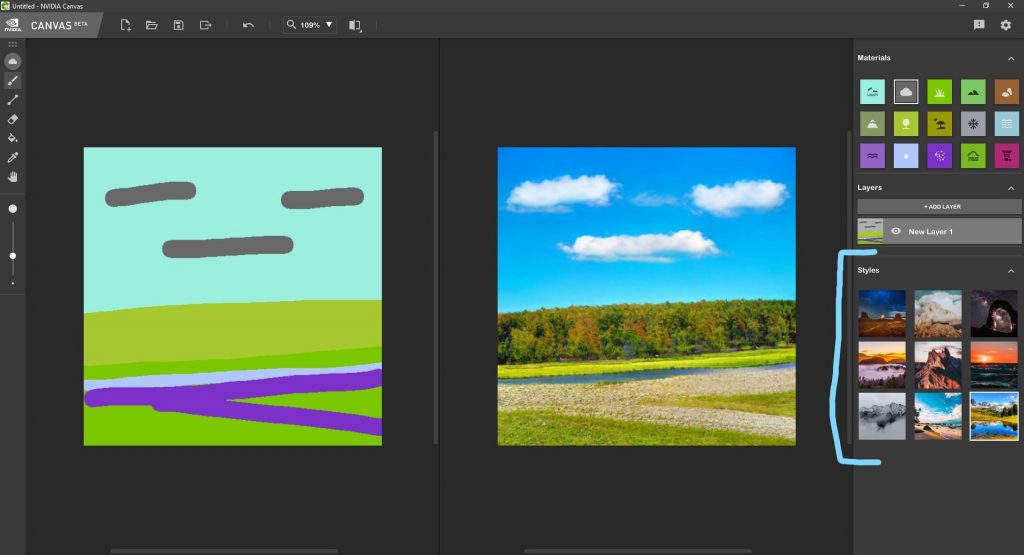
L’interfaccia è molto intuitiva, comunque ci preme segnalare che la sezione “Styles” è estremamente interessante.
L’Ai di NVIDIA infatti è stato allenato per ricreare ambienti casuali a partire da 9 diversi ambienti di esempio. Quindi qualsiasi sia la situazione di partenza (il nostro disegno), lui sarà in grado di ricreare 9 ambienti diversi sulla base dei nostri desideri. Ecco per esempio la nostra immagine di partenza come si comporta nei 9 stili.
Notevole vero?
Qua non si tratta di un filtro effettuato con photoshop, cambia proprio l’illuminazione di tutta la scena in base all’ora del giorno per cui l’Ai è stata allenata, cambiano la tipologia degli alberi, cambia il colore e la densità delle nuvole, in generale ogni singolo elemento e come si integra con la scena viene adattato grazie al training dall’intelligenza artificiale.
Ora passiamo a qualche esempio di immagine differente.
Ecco come si comporta NVIDIA Canvas in un ambiente di mare.
Ottimo risultato considerato che la creazione del pattern dell’immagine di sinistra a richiesto solo 4 click.
Sperimentiamo cosa succederebbe se cambiassimo il mare con l’acqua di fiume.
Interessante, l’acqua è più limpida e l’immagine sembra essere stata scattata dal basso e con un angolazione differente, più orizzontale. Da notare come il cambiamento dell’acqua ha influenzato anche gli oggetti vicini, come la sabbia, le rocce e addirittura il cielo. Canvas cerca sempre di fornire un immagine credibile partendo dai metadati che gli abbiamo fornito. Dato che l’acqua di fiume è più chiara, la luce si riflette sul fondale marino e illumina in maniera più intensa le rocce, che diventano più chiare. Il cielo invece cambia perché a quanto pare l’ai in presenza di un fiume ha osservato fotografie con cielo differente.
Cambiamo ora la sabbia con qualcos’altro.
Cambiare la sabbia con la foresta si rivela molto interessante, ora lo nostra immagine sembra essere stata scattata da molto in alto.
Rimettiamo la sabbia e proviamo a cambiare stile e impostarne uno in cui Canvas è stato allenato su ambienti serali.
Anche in questo caso il risultato è piuttosto credibile.
Forse vi sarete chiesti, cosa succederebbe se immettessimo nel pattern di sinistra qualcosa di irrealistico?
L’Ai non è stato addestrato per riprodurre una situazione in cui delle rocce levitassero nel cielo, e anche la sabbia sembra essere distorta in maniera innaturale. Comunque il risultato è curioso, e fornisce una buon esempio del perché l’allenamento dell’ai è importante, alla fine è quello che stabilisce quali situazione sarà poi in grado di riprodurre.
I requisiti
Canvas al momento è un software gratuito e in Beta. Per quanto non si sappia se la situazione rimarrà come la presente al termine del suo sviluppo, quello che sembra essere chiaro è che il requisito fondamentale rimarrà lo stesso. Una scheda video con tecnologia RTX di NVIDIA. Il motivo di questo requisito risiede nel fatto che le schede video di questa tipologia possiedono dei processori interni chiamati “RT Cores”, adibiti proprio ad effettuare calcolazioni di machine learning. Questo non vuol dire che queste operazioni non potrebbero venire eseguite con hardware differente, però questi microprocessori sono estremamente ottimizzati per questi particolari task.
Un’altra informazione interessante, al momento NVIDIA Canvas è in grado di esportare l’immagine in due formati: png e psd, ovvero il formato di progetto photoshop.
Le problematiche
NVIDIA Canvas è un software in beta, abbiamo le migliori speranze che in futuro esso venga aggiornato e migliorato. Quelle che si presentano immediatamente come le maggiori limitazioni di questo strumento sono principalmente due, la bassa risoluzione delle immagini (basta effettuare uno zoom del 150% per notare dettagli sgranati e simili), e la ridotta dimensione delle immagini, 512x512px. Al primo problema si può porre rimedio tramite photoshop, utilizzando magari un filtro che renda l’immagine più simile ad un dipinto che uno scatto naturale, ma per il secondo rimedio non c’è davvero alternativa. Tra l’altro il formato quadrato presenta molti problemi a livello di utilizzabilità in vari contesti.
Conclusioni
Abbiamo di fronte uno tool assolutamente innovativo. Ci poniamo quindi la domanda, le Ai in futuro andranno a sostituire le immagini stock? Supponendo che un algoritmo di Machine Learning possa riprodurre ogni genere di scenario, non solo naturale ma anche artificiale, è chiaro che la produzione automatizzata di un immagine stock sia molto più rapida ed economica rispetto ai metodi odierni. Inoltre Canvas è solo il primo di una lunga serie di strumenti che in futuro prenderanno piede nel mercato, ed è già molto promettente. Però per quanto riguarda le produzioni ad alto budget di contenuti multimediali, sicuramente il lavoro del fotografo e dell’illustratore 2d non andrà a scomparire, dopotutto per quanto la qualità di queste immagini sia già oggi sorprendente, è improbabile che si raggiunga la perfezione di un ambiente sviluppato da madre natura, o di un illustrazione prodotta con la creatività di un essere umano.
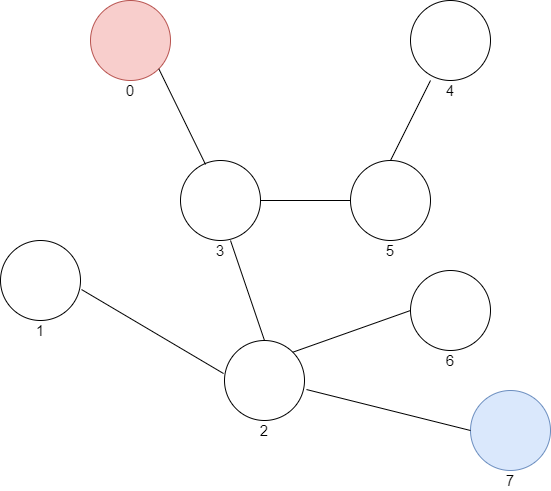
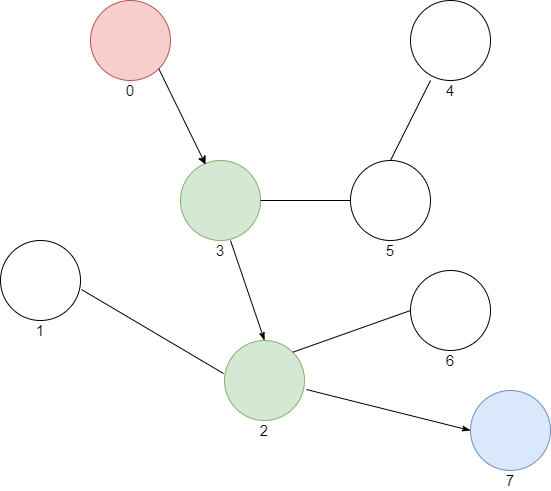
Supponiamo di dover lavorare ad un algoritmo che muove un nanobot all’interno del corpo umano. A livello microscopico, ogni cellula è rappresentata da un nodo all’interno di un grafo. Il nostro nanobot è in grado di organizzare il flusso di anticorpi muovendolo tra le cellule, alla ricerca di organismi maligni. Gli organismi maligni non sono intelligenti, ma cercano di prendere il controllo delle cellule per poter avere materiale con cui moltiplicarsi.
Si rende necessario di conseguenza agire velocemente, ovvero trovare il percorso migliore per raggiungere l’agente nemico.
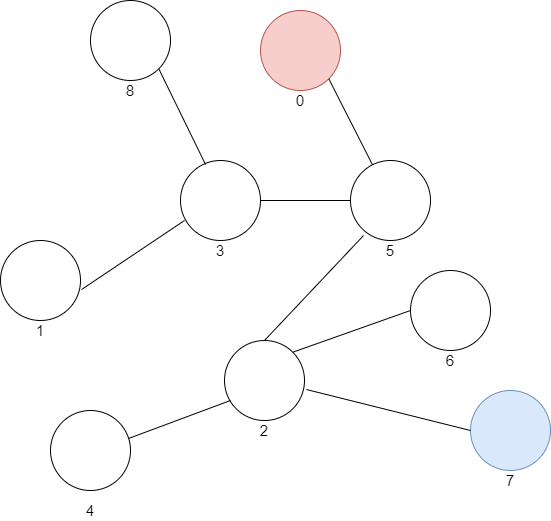
La situazione di base che utilizzeremo come esempio è rappresentabile con questo grafo:
Avete notato i numeri sotto i nodi? Rappresentano l’indice della cellula, il nostro programma dovrà cercare il percorso più efficiente per passare dalla cellula più vicina al nanobot (indice 0) a quella controllata dagli organismi maligni (indice 7).
L’algoritmo di Q-Learning
Il Q-Learning è una forma di machine learning indipendente dall’ambiente in cui viene utilizzata, ovvero l’algoritmo è generico, ed è possibile riutilizzarlo in diversi scenari.
Ci sono solamente stati ed azioni, in base agli stati della scena bisogna scegliere come muoversi.
Si deve costruire quindi una Q-Table, ovvero una tabella contenente azione e relativa reazione, che colleghi tutti gli stati possibili della simulazione con le possibili azioni del bot, assegnandone un punteggio.
Per insegnare al nanobot il percorso più efficiente, occorre fargli simulare molteplici viaggi fino a quando non avrà assegnato il punteggio corretto ad ogni azione.
Il codice
L’inizio del codice include l’importazione delle librerie. Ci è sufficiente il modulo “numpy”, una libreria di funzioni matematiche che ci faciliterà la gestione delle tabelle, che algoritmicamente parlando chiameremo matrici.
import numbpy as np
Creiamo quindi un percorso di esempio, assumendo che il bot lo possa ricostruire a partire dal mondo reale tramite i suoi sensori.
La variabile goal rappresenta l’indice della cella obbiettivo, che desideriamo far raggiungere al bot, quella contenente l’ipotetico agente maligno.
Dunque per la creazione della matrice R, ovvero la matrice rappresentante il valore del passaggio tra nodi del grafo delle cellule, occorre anche popolarla di zeri, e poi inserire il valore 100 alla casella goal.
MATRIX_SIZE = 8
R = np.matrix(np.ones(shape=(MATRIX_SIZE, MATRIX_SIZE)))
R *= -1
for point in points_list:
if point[1] == goal:
R[point] = 100
else:
R[point] = 0
if point[0] == goal:
R[point[::-1]] = 100
else:
R[point[::-1]]= 0
Questo significa che non verrà assegnato nessun punto al nanobot a meno che non raggiunga il suo obbiettivo.
Esiste anche il caso che dopo aver raggiunto l’obbiettivo, il nanobot si sposti nuovamente, e per eliminare questa problematica, è sufficiente aggiungere punti allo spostamento dal nodo goal a se stesso.
Impostiamo il parametro di apprendimento, che regola la variazione del punteggio, lo stato iniziale (indice 0 della cella 0), e definiamo la funzione available_actions, che restituisce tutte le scelte disponibili.
Per imparare a muoversi attraverso il corpo, all’inizio il nanobot si muoverà casualmente, quindi creiamo una funzione che scelga uno spostamento casuale.
Inoltre dopo essersi mossi casualmente, è necessario aggiornare i valori della tabella Q, che indica se vi ricordate il valore di una mossa in corrispondenza di uno stato.
A questo proposito scriviamo la funzione update, che dato uno stato, un’azione e il parametro di apprendimento, aggiorna la Q-table e calcola il punteggio attuale.
“Our humble video games industry has come a long way in the past twenty five years and, whilst we’ve seen a vast improvement in the quality of gameplay and story telling over the years, the graphical elements of these games has progressed at an even more alarming rate.”
The Evolution of Graphics in Video Games Over The Last 25 Years, George Reith, 17 Luglio, 2011
Rispetto a trent’anni fa, i videogiochi e le piattaforme di gioco hanno fatto progressi esponenziali a livello hardware e software. Dal punto di vista grafico, quello che una volta era un render di poche centinaia di pixel, ora viene generato tridimensionalmente tramite decine di migliaia di triangoli. La fluidità dell’azione, la qualità degli effetti visivi, del sonoro, non hanno paragoni.
Quello che invece purtroppo appare ancora piuttosto primitivo, se confrontato con le evoluzioni parallele nel suo campo, sono le Ai (Artificial Intelligence), che come descritto in un articolo del The New Yorker datato 19521, sono comparse già nei primi basilari videogiochi, ma che sono rimaste in genere grezze e irrealistiche. Non si tratta di una tecnologia che non è avanzata di pari passo con la grafica 3D, anzi, al giorno d’oggi tramite Ai si riescono a svolgere diverse funzionalità che nel secolo scorso erano considerate fantascienza. Tramite sofisticati software è possibile tramutare il testo in parola e il contrario, riconoscere animali, volti, eseguire guida autonoma su autoveicoli e assistere il volo di aeroplani. Ma perché tutti questi progressi non hanno preso piede con la stessa forza ed efficacia nel campo dei videogiochi?
L’applicazione più efficace dei concetti di Ai nei videogiochi è rappresentata dal Reinforcement Learning (RL), un algoritmo particolarmente efficacie in un ambiente virtuale, che implementa una rete di neuroni (per questo chiamata neurale), che viene specificamente allenata per raggiungere un obiettivo con una strategia ottimale. Strategia che non è lo sviluppatore a programmare, ma è la rete a imparare con l’allenamento e col passare delle generazioni (su questo ci torniamo tra poco). Combattere contro un avversario in un videogioco è divertente durante i primi incontri, utilizzando un Ai RL si otterrebbe un nemico con alte potenzialità adattive, capace di reagire alle mosse del giocatore anche quando lui segue tattiche originali e inattese dai game designer (coloro che si occupano di progettare il gioco a livello di meccaniche e interazioni tra uomo e ambiente virtuale). Una rete neurale viene allenata seguendo dei principi molto simili a quelli dell’evoluzione darwiniana, i vari neuroni rappresentano i geni del Ai, e questi non sono altro che un meccanismo, che alla ricezione di un input restituisce un output appropriato. Non si conosce a priori il modo in cui viene calcolato questo output, ma tramite molteplici generazioni di mutazioni casuali dei neuroni e la selezione dell’esemplare migliore, un Ai può imparare a risolvere un problema nella maniera più adeguata.
Più neuroni collegati in serie, immagine da wikipedia
Le potenzialità sono illimitate, e senza i limiti e le complessità del mondo fisico i game designer potrebbero dare libero sfogo alla propria fantasia. È facile immaginarsi missili a ricerca capaci di prevedere la posizione futura dei bersagli, milizie strategiche in grado di accerchiare e bloccare il giocatore, guerrieri medievali che eseguono finte ed evitano gli affondi nemici, e molto altro. Per essere chiari, il problema attuale delle intelligenze artificiali nei videogiochi non sta nel fatto che non siano complesse da battere, ma piuttosto risiede nel modo in cui questa difficoltà viene regolata. In un gioco digitale di carte come “Heartstone”, un titolo Blizzard molto celebre, un bot (programma ai) molto forte non è complicato da battere perché sa gestire meglio le proprie risorse o le sa usare in modo particolarmente intelligente, ma perché ha carte migliori nel mazzo rispetto al giocatore. In un gioco di guerra come “Call of Duty: Black Ops 3”, un soldato di difficoltà “realistica” rispetto ad uno di difficoltà “normale”, elimina più facilmente il giocatore per una mera questione di danni inflitti dall’arma. Questo tipo di difficoltà viene chiamato “difficoltà artificiale”, ovvero una sistema ideato dagli sviluppatori per regolare la complessità di un livello o di un nemico basato sulle statistiche, e non sull’intelligenza o le tattiche per affrontare il giocatore. L’esempio perfetto di come un Ai dovrebbe essere sviluppata può essere trovato in una qualsiasi implementazione del gioco degli scacchi, dove i vari livelli sono regolati con una differenza di Elo, e ad un incremento di Elo corrisponde un miglioramento del bot, ovvero una migliorata capacità di leggere i possibili stati successivi della partita. Per precisare però, un Ai utilizzata per lo scacchi o per altri giochi da tavolo, viene sviluppata tipicamente con un algoritmo diverso dal RL, come il MinMax o il MCTS (Monte Carlo Tree Search), algoritmi in grado di trovare la mossa migliore senza essere stati preventivamente allenati, ma la convenienza di questi metodi dipende dalla natura bidimensionale e ricca di stati precisi del gioco. Nonostante l’esistenza di diverse strategie per l’implementazione di intelligenze artificiali all’interno di videogame, molte società ogni anno evitano di aggiornare i propri NPC (Non Playing Character, controllati da software Ai), e si concentrano su altri aspetti più facilmente riconoscibili dall’utente finale.
Si potrebbe controbattere dicendo che la negligenza di un ben sviluppato aspetto incrementale della difficoltà, non è propria di tutte le compagnie di sviluppo videogiochi. In effetti in “Forza Horizon 4”, un gioco di guida open-world (mondo aperto, ampio, esplorabile) sviluppato dalla Microsoft nel 2018, le automobili sono guidate da un algoritmo di tipo ANN (Artificial Neutral Network), che viene regolato in base alla complessità selezionata nei settaggi di gioco, come viene descritto da questo articolo “Forza developers reveal how they make super-realistic AI drivers”2. Un algoritmo ANN corrisponde proprio a una rete neurale, ovvero come discusso in precedenza un Ai basata sul Reinforcement Learning. Molti giochi di guida in realtà, particolarmente quelli più simulativi, si basano sulle ANN, ma questo purtroppo non riguarda altri generi. Nel campo degli sparatutto, per esempio, la situazione è particolarmente disastrosa. Nella maggior parte dei giochi che rientrano in questa categoria i nemici si limitano a cercare qualche riparo, e lanciare una granata al giocatore nel caso lui faccio lo stesso. Tutto il resto del tempo lo dedicheranno a scaricare decine di caricatori con una mira infallibile e completamente meccanica nella direzione di qualsiasi cosa che si trovi tra loro e il giocatore. Un caso particolare è quello del gioco “Tom Clancy’s Rainbow Six: Siege” di Ubisoft, società Francese di sviluppo videogiochi, nota per la produzione su larga scala di titoli di ogni genere. La Ubisoft ha svolto un lavoro piuttosto basilare nel programmare i terroristi nemici, ma al contrario nel gioco di combattimento all’arma bianca “For Honor”, ha eccelso con Ai incredibilmente intelligenti, in grado di prevedere le mosse dell’avversario e agire di conseguenza. In generale il livello delle intelligenze artificiali nei videogiochi è estremamente incostante, in qualche gioco sia vecchio che recente si possono incontrare nemici molto astuti, che con meno risorse del giocatore riescono comunque ad essere pericolosi, mentre in altre produzioni si vedono NPC particolarmente stupidi e irrealistici (vedi “Cyberpunk 2077”, rilasciato nel 2020 da CD Project Red). Questo terribile stato delle cose è quasi indipendente dal genere di gioco, ed è poco influenzato dalla compagnia di produzione.
Gli NPC di cyberpunk non hanno problemi solo di intelligenza purtroppo
Qual è il motivo quindi che si nasconde dietro a questa incostanza, e come mai la maggior parte dei giochi non presentano Ai al passo coi tempi?
Per rispondere a questa domanda analizziamo, come esempio, l’evoluzione e i cambiamenti della famosa serie di videogiochi “Ratchet and Clank”, dello studio californiano Insomniac, che nel corso degli ultimi venti anni ha visto tre diverse generazioni di console e più di dieci pubblicazioni. A partire dal dispositivo Playstation 2 fino al più recente Playstation 5, col passare degli anni la potenza di calcolo è aumentata notevolmente, permettendo un numero di oggetti presenti sullo schermo e una quantità di poligoni di cui essi sono composti molto superiore. La storia si è evoluta e il gameplay è stato aggiornato continuamente per seguire gli standard del suo tempo. Quelle che invece sono rimaste quasi invariate sono le Ai.
In “Ratchet and Clank” si viaggia attraverso la galassia di un universo fantascientifico immaginario. La popolazione che si può trovare nei vari pianeti e nelle varie città è assolutamente passiva (al di fuori degli eventi pianificati dalla storyline) alla presenza e all’azione del giocatore, nei panni di Ratchet.
Tutta l’interazione che si può ottenere dalle Ai neutrali (che non attaccano il giocatore) consiste in qualche linea di dialogo (spesso una cinematica), indipendente dalla situazione e dalla condizione di arrivo. Non si viene complimentati se si sta giocando bene, non ci sono opzioni di dialogo dipendenti dalle missioni svolte in precedenza o altro.
Al di fuori del dialogo, quello che è possibile fare è tutt’al più colpire il personaggio per suscitare una qualche reazione verbale predefinita. Ci sarebbero moltissime funzionalità implementabili a livelli di interazione, come il pattugliamento dinamico di una zona, animazioni di “idle” (dall’inglese “inattività”, come respirare e guardarsi attorno), sincronizzate con i cambiamenti nell’ambiente virtuale circostante, sviluppare conversazioni in relazione con le statistiche di gioco (il numero di tentativi per livello, l’arma preferita e molto altro), ma nulla di tutto ciò è mai stato integrato nei vari giochi.
Per quanto riguarda le Ai nemiche, con lo scopo di inseguire, attaccare e eventualmente eliminare il giocatore, le strategie progettate dai game designer di Insomniac e successivamente implementate dagli effettivi developer, non hanno visto cambiamenti notevoli nel corso degli anni. I pattern di attacco e di pattuglia sono ancora rigidi e pre-programmati, i boss (nemici più complessi da affrontare, con particolari legami con la trama), hanno fasi di attacco e difesa che si alternano in modo prestabilito oppure completamente casuale, e i movimenti, le strategie costruite dal giocatore per affrontare un particolare scenario, hanno una influenza minima, se non proprio inesistente, sul comportamento dei nemici.
Quello che sta all’origine di una situazione stagnante come la presente, per quanto concerne le Ai, è una pura questione di mercato. Per pubblicizzare un prodotto di tipo videoludico, le caratteristiche principali sfruttate per favorirne la vendita sono la grafica, la storia, e il gameplay, in questo specifico ordine. Il funzionamento e il livello di intelligenza delle Ai risiedono nella categoria gameplay. Oltretutto, l’utente target delle compagnie di produzioni videoludiche, interessato ad un prodotto di questo genere, al momento dell’acquisto, anche quando giunge alla riflessione sull’aspetto di gameplay, non si interessa del funzionamento dei nemici. Probabilmente si preoccupa di come lui potrà agire all’interno del gioco (quali armi potrà usare, quali movimenti potrà sfruttare…), e di conseguenza da un punto di vista commerciale diventa ancora meno importante concentrarsi sull’aspetto Ai. Un caso diverso è quello dei simulatori di guida, dove la capacità degli avversari di rappresentare un ostacolo per il giocatore è decisamente influente anche nella qualità percepita del prodotto. Tutto questo processo di progettazione e propaganda non danneggerebbe in modo critico il prodotto finale, se la vera qualità dell’intrattenimento dell’utente fosse rappresentata dagli stessi valori utilizzati per la vendita, ordinati nella stessa maniera.
“Do Monster Hunter World’s disappointing graphics detract from gameplay? I don’t think so. I can see that the graphics are weak, I wish they were better, but I find the gameplay so enjoyable that I accept the game’s limitations and get on with the fun of playing”
Graphics And Gameplay Are About Mutual Interaction, Not Relative Importance, Kevin Murnane, 6 Febbraio, 2018
Il divertimento fondamentalmente è frutto di un buon gameplay, anche se sicuramente questo viene influenzato dalla qualità della storia, e bisogna ammettere che l’esperienza può essere migliorata anche da una grafica curata. Ovvero le metriche di effettivo gradimento di un videogioco sono poste in direzione diametralmente opposta rispetto a quelle usate per la sua promozione.
Alcune voci sono in disaccordo sull’argomento, l’aspetto grafico può per alcuni rappresentare un fattore talmente integrante di un videogioco, da non poter passare in secondo piano.
“The simple truth is you can’t separate gameplay from graphics, or vice-versa”
Graphics vs Gameplay, oldpcgaming.net, 3 Marzo 2015
La realtà è che un gioco non si identifica per quello che mostra, bensì per quello che permette di fare. Volare su un deltaplano, combattere a mani nude per le strade, questo è quello che offre un videogioco, ed è qualcosa che a volte la vita reale non permette facilmente di provare, o magari è qualcosa che un film non farebbe vivere in modo particolarmente immersivo. Innegabile è il fatto che la grafica può andare a migliorare un gioco, o a mostrare la sua età, motivo per cui anche nel campo videoludico esistono remake e remastered, i quali differiscono per cambiamenti puramente grafici (remastered), o evoluzioni anche nel gameplay (remake), nel caso anch’esso venga considerato troppo datato. Ma non è la grafica a fare il videogioco, questa è solo un modo in cui esso si interfaccia con l’utente.
Il primo luogo in cui la peculiarità delle intelligenze artificiali all’interno di un videogioco viene messa in esame, è in sede di recensione da parte degli enti giornalistici, che però nel settore dei videogiochi sono spesso parziali e prevenuti.
” When looking at reviewing companies such as Gamespot and IGN, the writers there always have a pedestal when they write their reviews and their articles”
Fix The Bias In The Gaming Industry, The Oddisey Online, Varnell Harris, 29 Aprile, 2019
La critica professionale e gli effettivi giocatori si trovano spesso in disaccordo
Un problema che causa molti altri difetti qualitativi in generale, in tutta l’industria videoludica. Il secondo e ultimo luogo è a casa dell’utente finale, che scoprirà che il gioco che ha comprato non è ben rifinito, o è una versione riciclata di quello dell’anno precedente. Purtroppo, siccome molti compratori sono giovani o sono inclini all’essere influenzati da una cattiva pubblicità, questa situazione non è facilmente in grado di cambiare. Allo stesso modo, fintantoché chi si occupa di produrre recensioni, si preoccupa principalmente di fare una buona impressione sul produttore per potersi accaparrare in futuro interviste esclusive e accessi anticipati, neanche da questa possibile sorgente arriverà una spinta per il cambiamento.
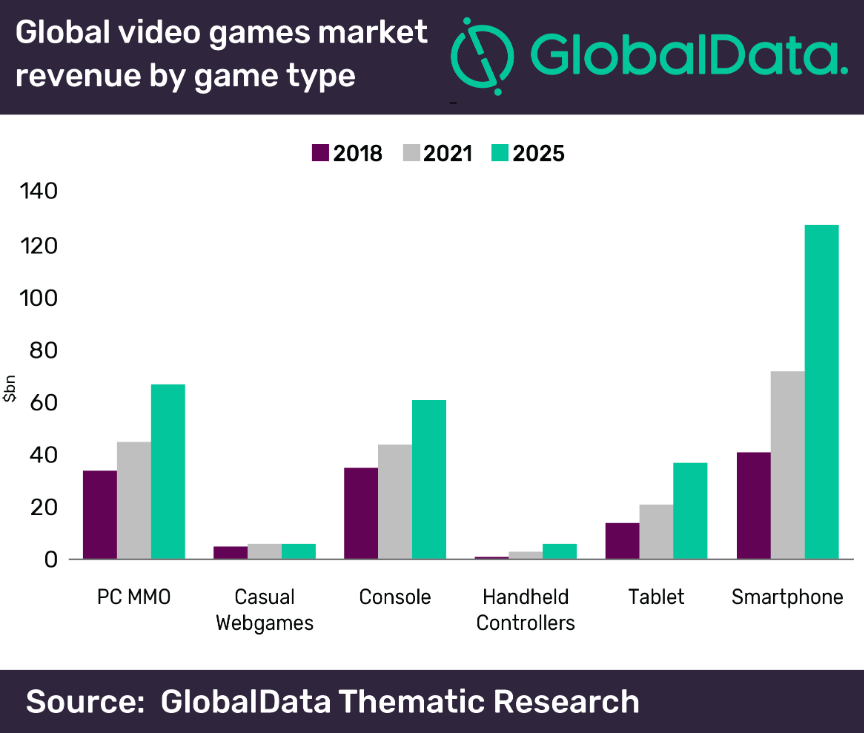
Probabilmente l’unica cosa che può variare la scala dei valori è il tempo, dopotutto i salti di qualità in termini di game design avvengono in modo molto più pronunciato con l’uscita di giochi completamente nuovi piuttosto che con la produzione di un nuovo capitolo di una serie ormai antica. In aggiunta, da un punto di vista grafico c’è un limite invalicabile a quanto aumentare la risoluzione, la qualità visiva di texture (le immagini applicate agli oggetti 3d) e il numero di poligoni, corrisponda ad un effettivo e percettibile miglioramento visivo, si parla infatti di “diminishing return”. Siamo già vicini a questo limite, da qualche anno è in commercio la tecnologia RTX, ovvero “Realtime Ray Tracing”, in grado di processare centinaia di fasci di luce in tempo reale (nell’intervallo fra un frame e l’altro), e generare di conseguenza ombre, riflessi e il risplendere di oggetti luminescenti. Questa tecnica software estremamente avanzata è presente nelle schede video delle ultime due generazioni, e rappresenta ad oggi un processo molto tassativo per le prestazioni, ma in futuro questo problema diventerà sempre meno presente. Un altro fattore determinante per il passaggio ad uno sviluppo più concentrato sul lato Ai sarà la completa saturazione del mercato dei videogiochi, che già oggi conta migliaia di giochi rilasciati ogni anno, si tratta infatti di un’industria in forte crescita, “Video Games Could Be a $300 Billion Industry by 2025 (Report)”5, probabilmente si cercherà di creare meno prodotti ma di qualità. Quando questo processo prenderà finalmente piede, sicuramente le intelligenze artificiali, la loro peculiarità e livello di complessità, assumeranno una posizione di maggior rilievo.
Un trend in forte crescita
Cosa aspettarsi dal futuro quindi? Ci sarà sicuramente una rivoluzione dello sviluppo videogiochi su larga scala, trasformazione che avverrà nel giro di tre, cinque anni, grazie anche all’uscita di “Unreal Engine 5”, un engine per lo sviluppo videogiochi di grande rilievo che secondo la software house di appartenenza Epic Games includerà tecnologie come Nanite, che Epic introduce in questo modo: “Nanite virtualized micropolygon geometry frees artists to create as much geometric detail as the eye can see”4, e grazie anche all’uscita di nuove schede video NVIDIA e AMD sempre più potenti. Ulteriore fattore determinante sarà il crescente utilizzo di macchine a guida autonoma, dalle Youssef Maguid, associate communications specialist alla Ubisoft:
“Just as videogames can provide insight to improve real-world systems, those same systems can feed data back into videogames to help create more immersive and realistic experiences”
How Ubisoft is Using AI to Make Its Games, and the Real World, Better, Youssef Maguid, 23 Marzo, 2018
In sostanza come per allenare le Ai presenti nei computer di bordo dei veicoli a guida autonoma si utilizzeranno ambienti virtuali, le stesse automobili nutriranno i sistemi digitali coi dati raccolti dai milioni di utenti alla guida, e la simulazione del traffico nei videogiochi diventerà più realistica. Ci sono quindi ottime speranze per quanto riguarda il futuro delle intelligenze artificiali nei videogiochi, e saranno le aziende che riusciranno ad adottare per prime questi straordinari strumenti, a sopravvivere alla prossima generazione di giochi.
Leonardo Bonadimani – Whatar – Filosoft
1The New Yorker, 2 agosto, 1952, p. 18
2Forza developers reveal how they make super-realistic AI drivers, Dexerto.com, Kieran Bicknell, 28 Ottobre, 2020
3Video Games Could Be a $300 Billion Industry by 2025 (Report), Variety, Liz Lanier, 1 Maggio 2019
4A first look at Unreal Engine 5, Unreal Engine Blog, 15 Giugno, 2020
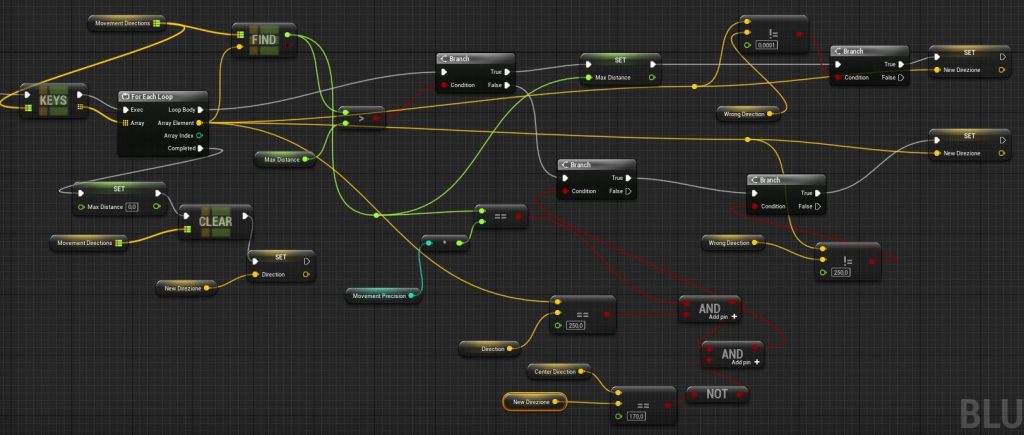
Ai per uno zombie in Unreal Engine 4, un approccio migliore di “AiGoTo” in Blueprint
Quando si tratta di preparare strumenti per giovani sviluppatori senza esperienza, Unreal Engine 4 eccelle, è possibile infatti anche senza nessuna conoscenza di pathfinding, posizionando un semplice NavMeshBound e chiamando la funzione predefinita AiGoTo, far muovere un Ai in modo dinamico, fargli automaticamente evitare gli ostacoli, e con pochi blocchi in più, addirittura inseguire il PlayerCharacter.
Però chi ha già testato questo sistema, sa che non è il massimo. Non solo il movimento delle Ai è meccanico, irrealistico, ma inoltre se utilizzato per creare un orda di nemici, essi non faranno altro che inseguire il Player in fila indiana, diventando estremamente prevedibili, facili da evitare, e particolarmente sgraziati.
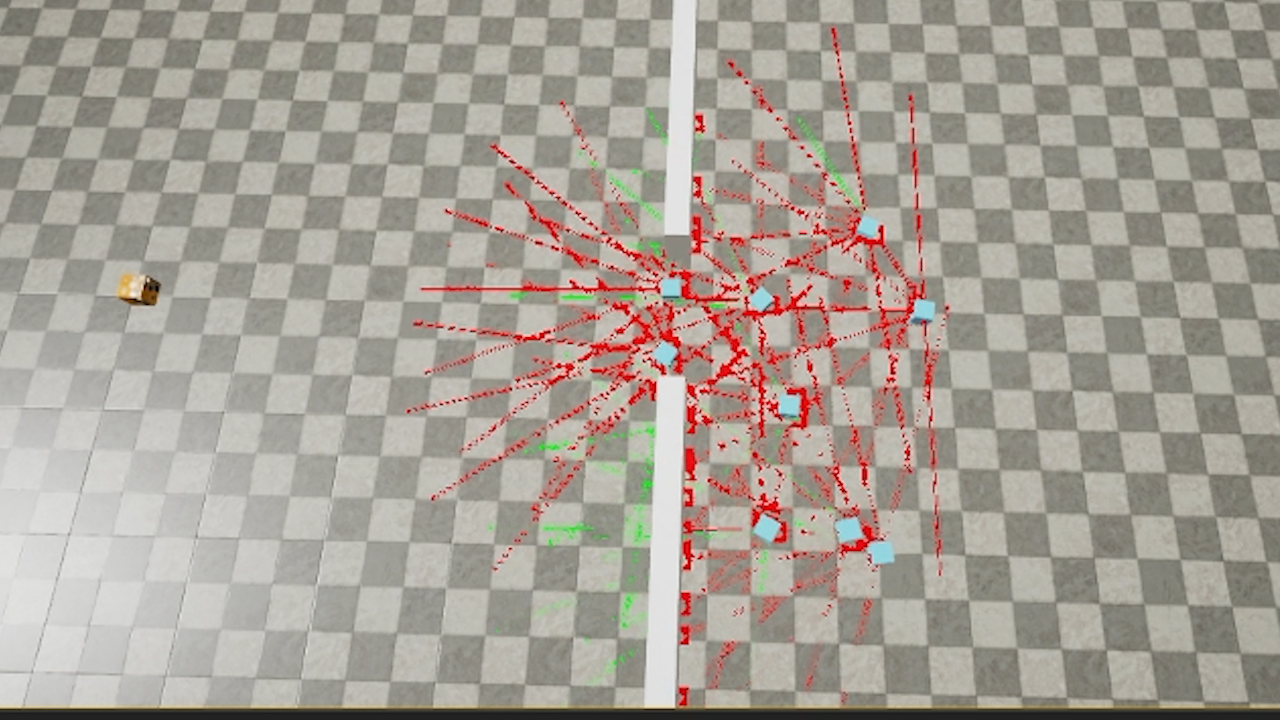
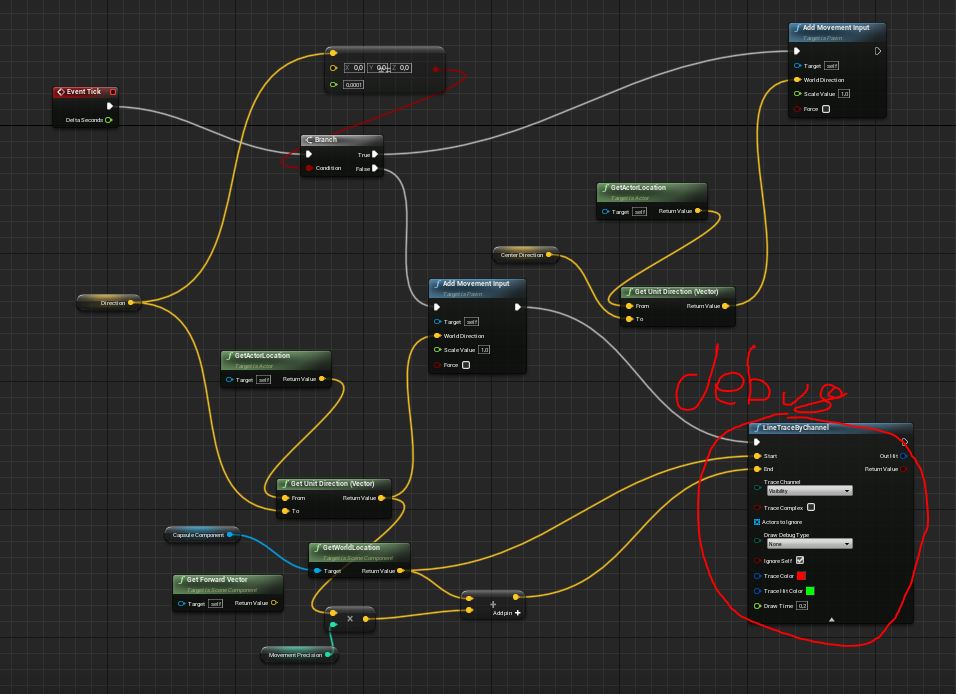
Senza andare a codificare un complesso algoritmo di pathfinding, in grado di risolvere labirinti o trovare la strada migliore per raggiungere il target, si può comunque ottenere un risultato più efficace per questo caso specifico, utilizzando delle linee tracciate dal centro dell’agente verso diverse direzioni (LineTraceByChannel), controllando la distanza tra un Ai e eventuali ostacoli, ed effettuare scelte di conseguenza.
In questo modo se diversi agenti stanno inseguendo il Player, essi non solo cercheranno di evitare gli ostacoli, ma tratteranno gli altri agenti stessi come tali, cercando di distanziarsene, formando così un’orda ampia e minacciosa.
Abbiamo riportato qua sotto la nostra soluzione, ma ci sono diversi approcci per ottenere questo effetto.
Gli ingredienti per un Ai personalizzabile
Quello che ci serve per sviluppare e testare questo algoritmo è:
Un livello con un piano e degli ostacoli posti su di esso
Un player character che spawna all’inizio della partita
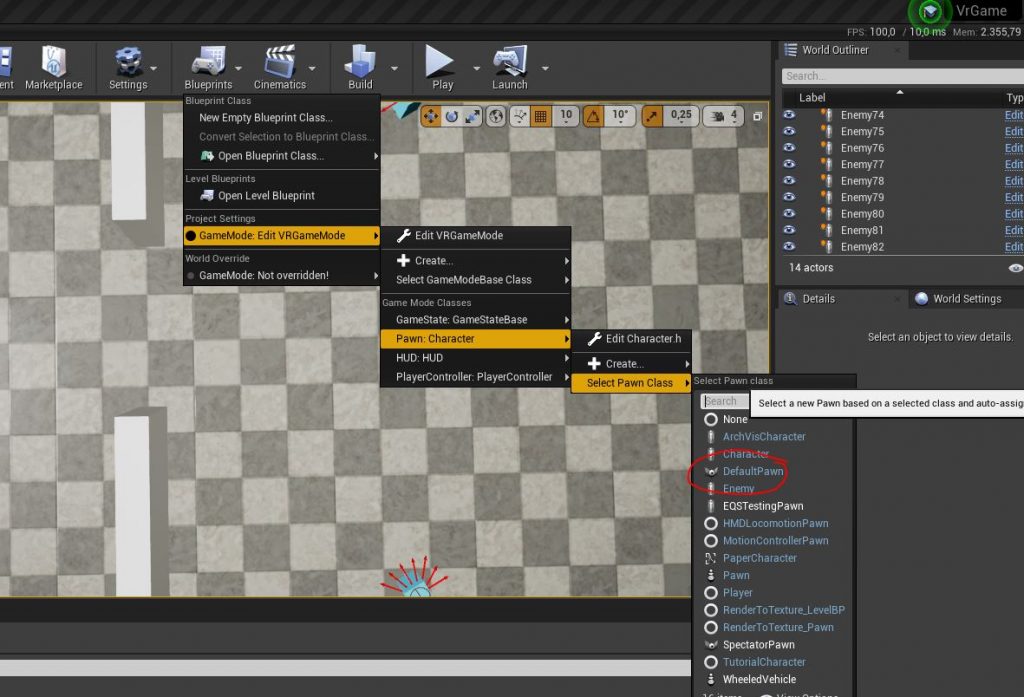
Il Pawn del livello impostato a DefaultPawn (indicazioni più precise a seguire)
Un nuovo Actor vuoto di classe Character
Ecco come impostare il Pawn a DefaultPawn:
Questo ci servirà per osservare il comportamento degli agenti dall’alto, e avere una migliore visuale di cosa sta accadendo.
Bene, ora rechiamoci nel Blueprint del nostro “zombie”, che d’ora in poi chiameremo Z, e prepariamoci all’azione.
L’agente Z
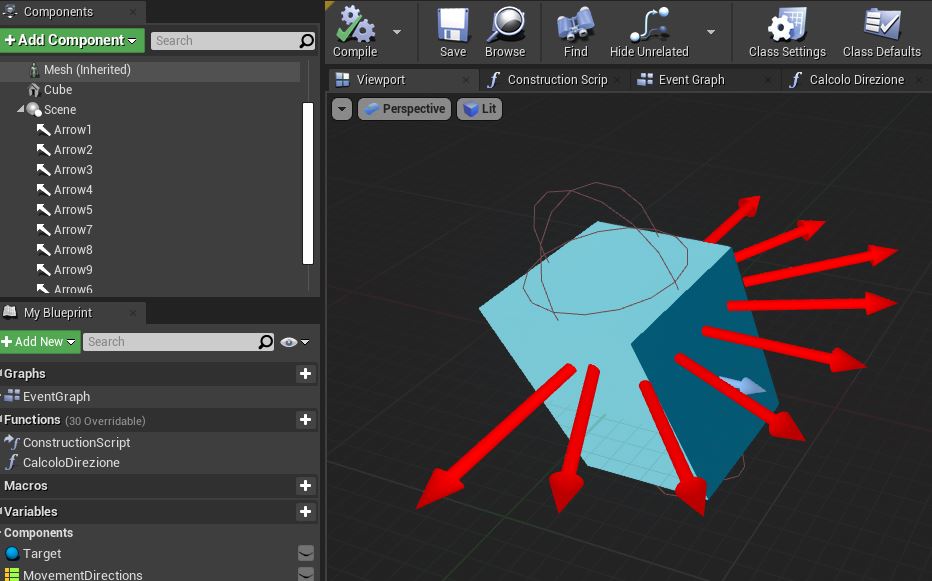
Dopo aver opportunamente creato un nuovo Actor di classe Character, aggiungiamo una serie di componenti che ci serviranno più avanti.
Queste frecce saranno il punto di partenza e la direzione da cui tracciare le linee che utilizzeremo per prevedere le collisioni con eventuali ostacoli.
Da notare che le frecce sono impostate come figli di “Scene”, un componente senza effetti sul mondo di gioco ma dallo scopo di raggruppare le varie Arrow per rotazione, traslazione e scala.
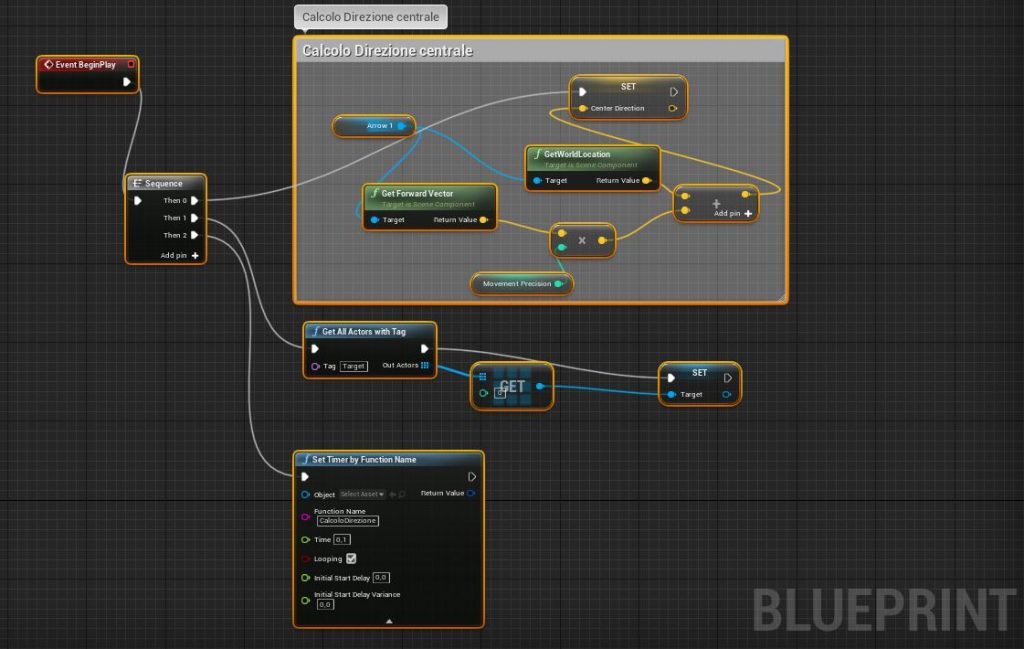
Event BeginPlay
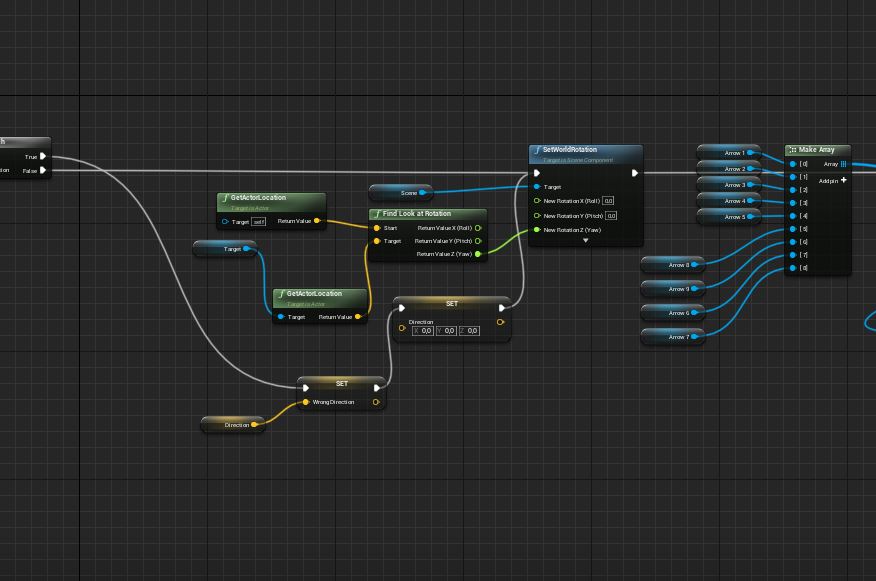
Prima di tutto, dobbiamo preoccuparci di muovere Z in una direzione neutra, ovvero diritto contro il bersaglio, quando non si hanno ancora informazioni, o la direzione ottimale non è stata ancora calcolata.
Inoltre salviamo il primo attore che compare nella lista degli attori con tag “Target”. Questo può essere cambiato più tardi inserendo una qualche logica per scegliere il bersaglio preferito dalla lista.
Infine impostiamo che la funzione di calcolo della direzione “CalcoloDirezione” che creeremo successivamente si aggiorni ogni 0,1 secondi (è possibile inserire un delay migliore ma lo script diventa più pesante, più Ai si hanno maggiore deve essere il delay).
Event Tick
Ogni frame, dovremo aggiornare la direzione di movimento di Z con quella ottenuta dalla funzione
Come debug possiamo usare un LineTraceByChannel con visibility “Per duration” che abilitiamo solo quando vogliamo vedere dove effettivamente sta andando Z. Quando non dobbiamo verificare questo dato, la visibility deve essere settata a “None”. Questo anche perché siccome possiamo impostare che Z scivoli sul terreno invece che curvare in modo rigido, così diventa più chiaro capire dove sta puntando. Inoltre se ci fossero diversi agenti Z che si incastrano tra di loro, questa traccia ci indica come mai non si sbloccano.
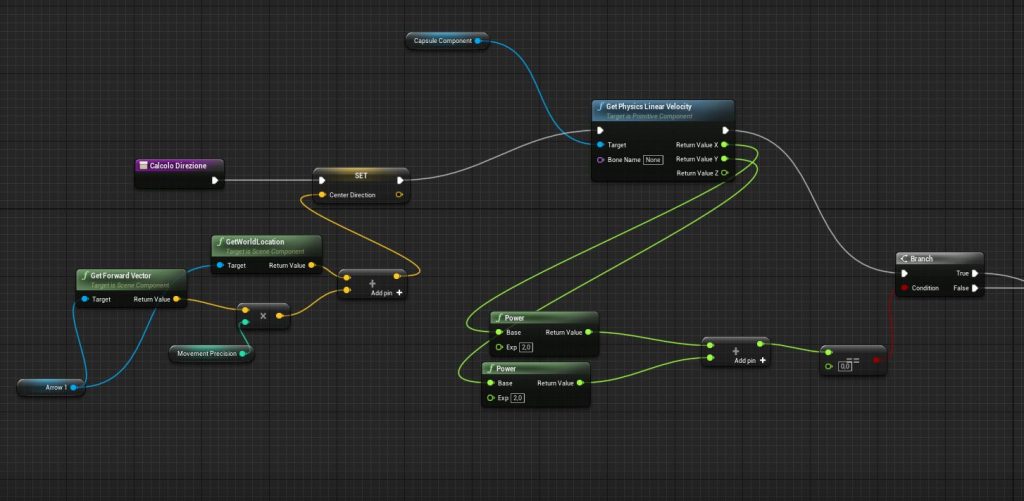
La funzione “Calcolo Direzione”
Partiamo dal calcolare nuovamente la direzione centrale, dopodiché controlliamo se Z è fermo
Se Z è fermo resettiamo la variabile WrongDirection, e resettiamo Direction. Questo vedremo fra poco che ci servirà per capire se Z è bloccato.
In ogni caso ruotiamo “Scene” (il componente a cui sono attaccate tutte le frecce che abbiamo aggiunto precedentemente), nella direzione di Target, in modo da effettuare i controlli a partire dalla direzione in cui desideriamo mandare Z.
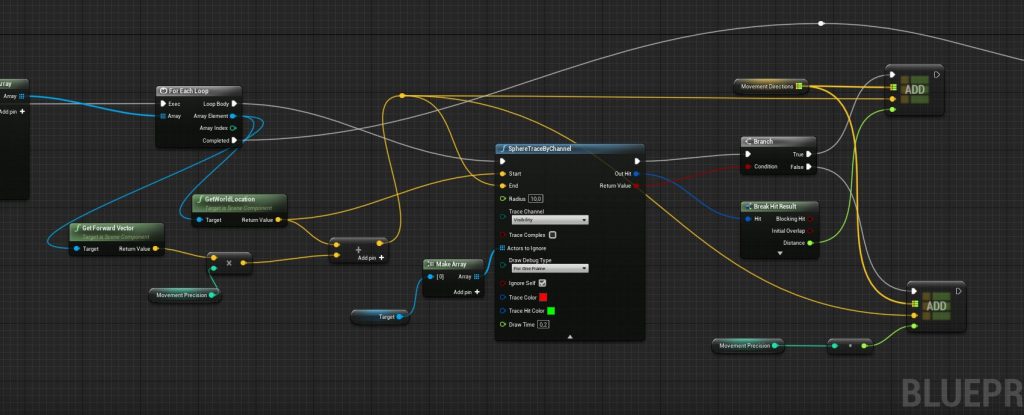
Come ultimo passaggio in questa schermata, creiamo un array di tutte le frecce che useremo per verificare le collisioni nell’immediato futuro.
Per ogni freccia verifichiamo la collisione, e salviamo il risultato nella mappa “MovementDirection”.
Ok, ora dobbiamo solo scegliere la direzione migliore
Questo ultimo passaggio è un po’ complicato, ma in sostanza ci occupiamo di scegliere la direzione in cui andare prediligendo:
il centro, se non ci sono ostacoli
la direzione dove l’ostacolo non è presente più vicina al centro di Z
la direzione dove l’ostacolo è posto a distanza maggiore in caso ci siano ostacoli in tutte le direzioni
se abbiamo già una direzione salvata in memoria, e non siamo incastrati, e il centro ancora non è libero, continuiamo in quella direzione
Un piccolo video dimostrativo:
Come vedete non solo le Ai non si mettono in fila indiana per inseguire il Player, ma sono anche in grado di seguirlo mentre salta o è in volo, un’altra funzione che AiGoTo non supporta!
Da notare che per un risultato ancora migliore bisognerebbe evitare nel controllo degli ostacoli le Ai stesse quando la distanza dal Player è più alta di un certo limite (o non risultano visibili), per farli incastrare meno, arrivare più velocemente e salvare tempo di computazione.
Quanto sarebbe divertente collegare una videocamera ad un arduino, e registrare una partita a poker, a dama, a scacchi…
Si potrebbe creare un arbitro computerizzato, sfruttando anche il Text-To-Speech per segnalare verbalmente i bari, creare un ai che calcola la mossa migliore e ti segnala quando la hai scelta, o fa un suono triste quando sbagli grossolanamente.
Per fare tutto questo, oltre naturalmente a creare un programma magari python (il nostro linguaggio di prima scelta) per collegarsi alla webcam e raccogliere il feed video, c’è bisogno di fare data pre-processing.
Data pre-processing
Purtroppo perché un ai sia in grado di riconoscere il campo da gioco, le carte e tutto il resto, non è sufficiente analizzare il feed video puro, bisogna togliere tutto ciò che rappresenta dati inutili, o che potrebbero facilmente confondere il nostro algoritmo.
“Garbage in, garbage out”
Con dati sporchi, ricchi di errori, si ottengono risultati sporchi e ricchi di errori
Ecco che entra in azione il data pre-processing, ovvero una procedura di filtraggio intenta proprio ad ottenere questi risultati.
Image filtering con python
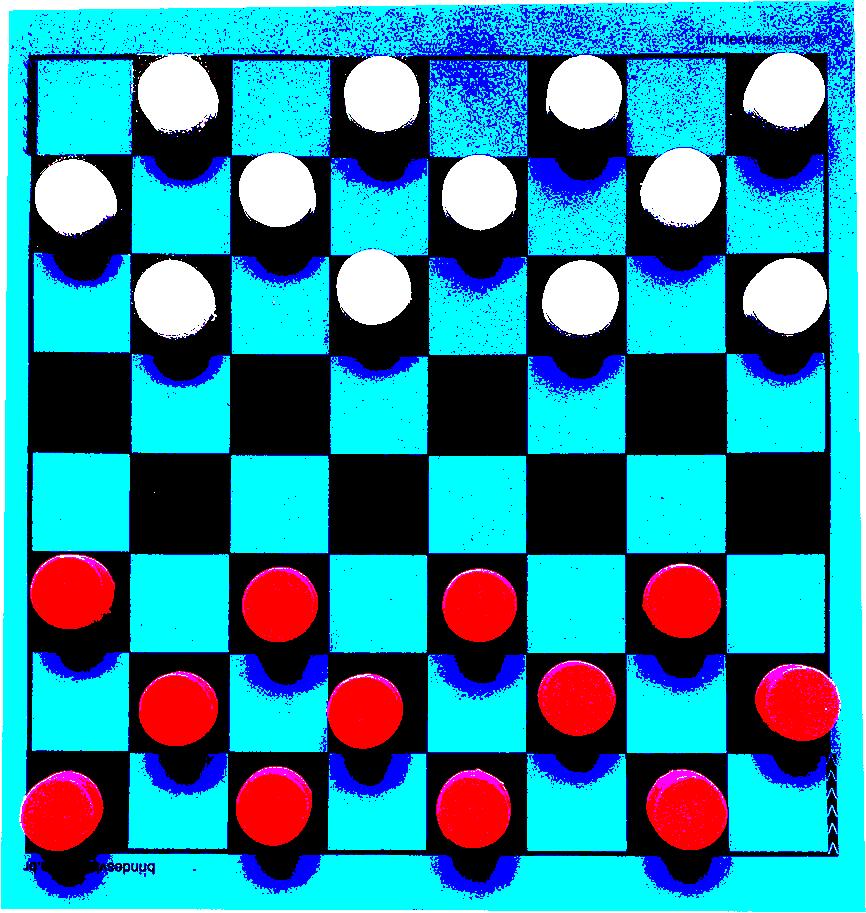
Prendiamo come esempio un immagine ottenuta da un ipotetica telecamera posta sopra ad una scacchiera e i pezzi per la dama.
Supponiamo di dover far riconoscere all’ai le caselle e le dame di entrambi i giocatori, per farlo bisogna usare l’image recognition IR, però se guardate attentamente, ci sono tre diversi problemi che potrebbero confondere un ipotetico algoritmo:
le ombre che l’illuminazione traccia sul campo confondono in parte le caselle
le pedine sia bianche ma soprattutto rosse non sono esattamente dello stesso colore e sulla superfice presentano granulosità
la videocamera non visualizza le pedine tutte dalla stessa angolazione
Due dei problemi che potremmo avere sono risolvibili filtrando l’immagine, però le ombre purtroppo essendo scure e essendo spesso tracciate su caselle nere, rimarranno un problema, anche se in misura minore, che potremo però aggirare in un altro modo.
L’obbiettivo
Dobbiamo fondamentalmente rendere le superfici della dame perfettamente regolari, in questo modo potremmo riconoscerle semplicemente dando in pasto all’algoritmo di IR due cerchi, uno rosso e uno bianco, ed esso escluderà automaticamente le parti inclinate che ci davano fastidio.
Il codice
Partiamo dalle dipendenze di questo progetto:
from PIL import Image
import numpy as np
import time
Sia numpy e pil si possono installare lanciando pip3 install PIL e pip3 install numpy da terminale.
Per quanto riguarda time, non solo si tratta di una libreria già presente nell’installazione base di python3, ma è anche facoltativa, in quanto la useremo solamente per calcolare l’efficienza del nostro algoritmo.
Ora la nostra immagine è salvata dentro image, i suoi dati in formato di array di numpy sono salvati dentro img_data, la altezza è h, la larghezza è w e il numero di componenti del singolo punto (3 con immagini RGB, 4 con immagini RGBA), sono salvati in t.
Possiamo fare un po’ di debug aggiungendo un print:
print(h, w, t)
Che ci restituirà in output:
>> 913 866, 3
Ottimo, quindi la nostra immagine è alta 913, larga 866 e non ha la trasparenza (si poteva già prevedere, considerando che si tratta di un jpg).
Ora prepariamo un nuovo array di numpy vuoto, pronto a raccogliere i pixel dell’immagine rielaborata.
Quindi creiamo un iterazione in cui eseguiamo un ciclo per ogni pixel all’interno dell’immagine. Raccogliamo intanto la lista dei tre valori (R, G, B) che formano il pixel.
for x in range(w):
for y in range(h):
r_pixel = img_data[y][x][0]
g_pixel = img_data[y][x][1]
b_pixel = img_data[y][x][2]
Ora supponendo che non sia possibile posizionare perfettamente la videocamera, potrebbe essere necessario effettuare uno zoom sul soggetto, imponiamo dunque una regola che ci permetta di analizzare solo le zone interessanti.
if x in range(0, w) and y in range(0, h):
Per ora abbiamo inserito w e h come estremità del range per includere tutta l’immagine, se serve per esempio tagliare i bordi a sinistra e a destra di 200px basterebbe sostituire il primo range con range(200, w-200).
Siamo arrivati al filtro vero e proprio. Per la nostra immagine abbiamo trovato che per regolarizzare abbastanza i colori si può eseguire un’operazione di questo genere,
r = (255, 0)[r_pixel < 100]
g = (255, 0)[g_pixel < 100]
b = (255, 0)[b_pixel < 100]
new_img_data[y][x] = [r, g, b]
In sostanza salviamo 255 ovvero intensità massima per ogni colore, solo se il colore stesso parte da un intensità non troppo elevata.
Il programma completo, con l’aggiunta del caso in cui siamo fuori dal range interessante e la produzione effettiva dell’immagine risulta così.
from PIL import Image
import numpy as np
import time
image = Image.open("photo.jpg")
img_data = np.array(image)
h, w, t = img_data.shape
print(h, w, t)
new_img_data = np.zeros((h, w, t), dtype=np.uint8)
for x in range(w):
for y in range(h):
r_pixel = img_data[y][x][0]
g_pixel = img_data[y][x][1]
b_pixel = img_data[y][x][2]
if x in range(0, w) and y in range(0, h):
r = (255, 0)[r_pixel < 100]
g = (255, 0)[g_pixel < 100]
b = (255, 0)[b_pixel < 100]
new_img_data[y][x] = [r, g, b]
else: #siamo fuori dal range
new_img_data[y][x] = [255, 255, 255] # pixel bianco
print("Process time: " + str(time.process_time()) + "s")
new_img = Image.fromarray(new_img_data, 'RGB')
new_img.show() # visualizza l'immagine a video
new_img.save("new_photo.jpg") #salva la nuova immagine
Che produce questo risultato:
Perfetto, adesso come preventivato con dei semplici cerchi rossi e bianchi possiamo riconoscere tutte le pedine.
E la scacchiera? La scacchiera in realtà non serve, una volta riconosciuta la pedina nella relativa posizione, basta controllare in che range di pixel rientra, per capire in che casella risiede.
Ancora non soddisfatti? Si può ottenere un immagine con ancora meno disturbo effettivamente, togliere completamente ombre e scacchiera, e tenere solo le pedine, quello che davvero ci interessa.
Per farlo è sufficiente modificare il filtro:
r = (255, 0)[r_pixel > 207]
g = (255, 0)[g_pixel > 207]
b = (255, 0)[b_pixel > 207]
Per ottenere il seguente risultato.
Ora è impossibile che l’algoritmo si confonda. Direste mai che questa foto è stata scattata ad una scacchiera di dama?
Avete notato un trend? Meno l’immagine è riconoscibile dall’umano, più è riconoscibile dalla macchina. Questo perché noi siamo in grado di dare molteplici significati con relativamente alta precisione, mentre una macchina non è in grado (ancora) di analizzare più di un dettaglio su un immagine senza applicare nessun filtro. Se si vogliono analizzare le ombre bisogna togliere tutto il resto, se si vuole capire quanti tasselli ha un puzzle bisogna togliere i colori, e così via. Dopo molti filtri e diverse analisi si ottiene il risultato che un umano in genere ricava con un solo sguardo.
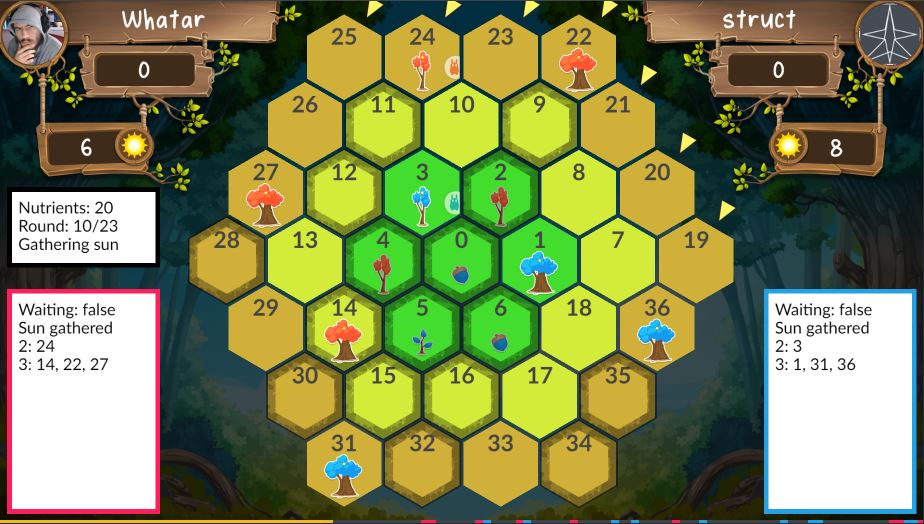
In questo articolo andremo a osservare e commentare la challenge proposta su https://www.codingame.com/multiplayer/bot-programming/spring-challenge-2021 e alcune interessanti strategie per risolverla.
Codingame è un sito estremamente affascinante, che raccoglie sfide di ogni genere che non solo possono risultare piuttosto dilettevoli, ma allenano la capacità di creare algoritmi e di codificare gli stessi in diversi linguaggi.
Da code golf all’ottimizzazione, su codingame.com ci si può cimentare nella risoluzione di problemi di diverso tipo, ma quelli che più ci interessano riguardano la scrittura di Ai.
Il sito presenta due volte all’anno una challenge di 10-11 giorni in cui i bot (programmi Ai) di due programmatori dovranno scontrarsi per scalare la classifica.
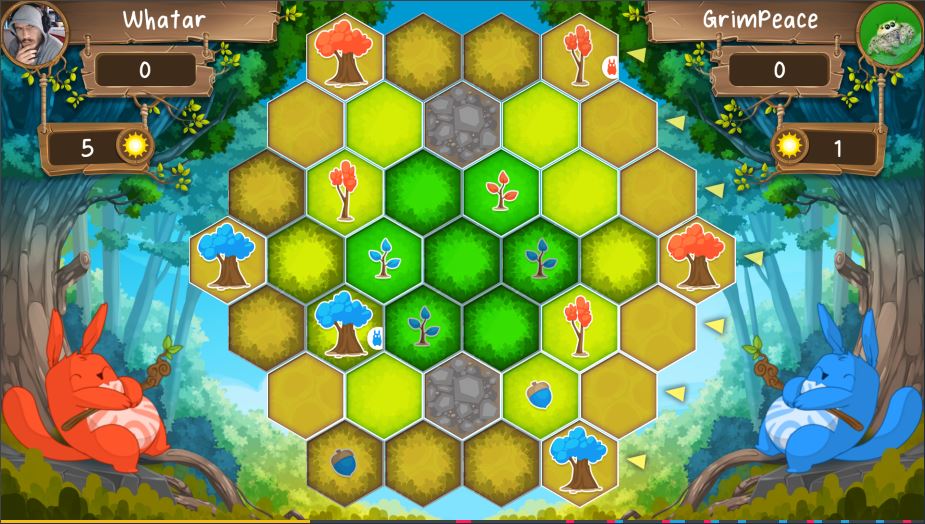
La challenge di quest’anno fa impersonare dai nostri codici uno spirito della foresta ispirato dall’iconico Totoro di Hayao Miyazaki, il suddetto spirito, istruito dai nostri comandi, dovrà gestire il ciclo naturale della semina, crescita e passaggio a miglior vita degli alberi della sua radura. In questo articolo andremo a parlare degli algoritmi a livello logico che permettono di superare le leghe “legno II”, “legno I” e “bronzo”, ma sarete voi a dovervi ingegnare per codificare queste strategie, poi per argento e oro vi serviranno idee tutte vostre.
Tutti gli esempi di codice, e le citazioni alle variabili riportate in questo articolo saranno in python3.
Le regole…
Qui riportiamo le regole che riteniamo più importanti per la risoluzione (quantomeno logica) del problema. C’è da sottolineare che man mano che il nostro algoritmo avanzerà di lega battendo i vari boss, il gioco si andrà a complicare sempre più, aggiungendo nuove regole.
Innanzitutto conviene scegliere uno Starter Kit scritto nel linguaggio di programmazione che si vuole adoperare, poi possiamo metterci all’opera.
…della lega legno II
Si possono completare alberi di grandezza = 3
Si possono fare infinite mosse all’interno di un giorno di gioco
Completare un albero costa 4 soli
Ogni albero ci da x punti sole ad inizio turno, dove x è la grandezza dell’albero stesso
Tutte le mosse legali sono elencate negli input
La partita dura un giorno
Si guadagna 1 punto per ogni 3 punti sole risparmiato a fine partita
Si guadagnano più punti al completamento di un albero se l’albero è piantata in una cella con cell.richness maggiore
La prima lega di una challenge su codingame.com in genere è molto semplice, qui vediamo che gli unici comandi che abbiamo a disposizione sono il completamento con
print("COMPLETE #indicecella")
Dove #indicecella sta per il numero della cella dove risiede l’albero da completare, e
print("WAIT")
Per concludere il proprio turno, quando entrambe le Ai avranno completato il proprio turno, il giorno diventerà il successivo, se game.day sarà uguale all’ultimo giorno della partita, la partita si concluderà.
Ad inizio partita, tutti gli alberi in questa lega saranno di dimensione tre, ovvero saranno completabili.
A questo punto dobbiamo porci la domanda, come facciamo a battere Totoboss?
L’algoritmo per uscire da legno è semplice, dobbiamo semplicemente completare gli alberi in ordine da quelli nella zona con cell.richness maggiore, a quelli nella zona con cell.richness minore.
Ps. in realtà anche eseguendo l’ultima azione disponibile in game.possible_actions, senza sapere ne leggere ne scrivere, siamo riusciti a raggiungere legno I senza sforzi, ma scegliere di completare l’albero migliore ci aiuterà in futuro.
…della lega legno I
Ci sono 6 giorni di gioco
Si possono far crescere gli alberi
Il sole ruota attorno alla radura (un giorno, uno spostamento)
Riportiamo le regole di crescita:
Grow action
Growing a size 1 tree into a size 2 tree costs 3 sun points + the number of size 2 trees you already own.
Growing a size 2 tree into a size 3 tree costs 7 sun points + the number of size 3 trees you already own.
Non preoccupiamoci del comportamento del sole per ora
Chiaramente anche qui come prima dobbiamo prediligere la crescita degli alberi su un terreno con cell.richness migliore, e poi completarne il più possibile.
…della lega Bronzo
Si possono piantare semi
il costo di piantare un seme equivale al numero di propri semi già presenti in campo
Gli alberi fanno ombra sulle zone circostanti in base alla propria grandezza.
Non otteniamo punti sole dagli alberi sotto l’influsso di un’ombra creata da un albero di grandezza uguale o maggiore
La partita consiste in 24 giornate
Si ottiene un bonus per ogni pianta completata che diminuisce mano a mano che più piante vengono completate
Il motivo per il quale il sole gira attorno alla radura vi sarà ormai chiaro. Qui il gioco si fa dura, per arrivare ad argento bisognerà fare in modo che:
I semi che si andranno a piantare copriranno uno spazio ampio, in modo che si eviti il rischio di fare ombra ai propri stessi alberi
Il costo delle varie azioni deve essere ottimizzato, per riuscire a piantare e completare il numero massimo di piante
Si completino la piante prima del proprio avversario, per sfruttare a meglio il bonus
Osservando la griglia di debug del campo di gioco, possiamo formulare matematicamente alcune condizioni per svolgere le varie azioni, in modo da adempire ai vari requisiti precedentemente discussi.
Per cominciare, un ottima strategia per evitare di ostacolarsi da soli tramite le ombre, è obbligare l’algoritmo a non piantare in celle che rispondono alla condizione action.target_cell_index in cell.neighbors dove la cella in esame è cell = action.origin_cell_index.
Un altra condizione interessante da implementare è quella che un seme non dovrebbe essere piantato in linea retta (per esempio 25, 11, 3) rispetto ad un altro albero di nostra proprietà, perché nei round futuri esso sarebbe posto all’ombra.
Inoltre siccome piantare un seme non costa punti sole solo se non ci sono altri nostri semi in gioco, conviene piantarne uno solo in questo particolare caso.
Infine riguardo alla tempistica, abbiamo scoperto che iniziare a completare alberi dal round 12 sembra proficuo, mentre fino all’ultimo round è conveniente avere sul terreno sempre almeno 3 alberi, per non rischiare di avere troppi pochi i punti sole generati ad inizio turno. Non eccedere invece mai invece il limite di 6/8 alberi piantati, oltre quel numero le ombre sul campo iniziano a diventare troppe e si rende impossibile tenerne traccia.
Se volete battere il sottoscritto dovete raggiungere le prime 150 posizioni della lega oro.