






Python QTable lavorare coi grafi
Oggi ci occuperemo di un primo algoritmo Ai di reinforcement learning.
Il nostro progetto ha preso ispirazione da questo analogo algoritmo di pathfinding in python.
Il modello che analizzeremo è piuttosto semplice.
Supponiamo di dover lavorare ad un algoritmo che muove un nanobot all’interno del corpo umano. A livello microscopico, ogni cellula è rappresentata da un nodo all’interno di un grafo. Il nostro nanobot è in grado di organizzare il flusso di anticorpi muovendolo tra le cellule, alla ricerca di organismi maligni. Gli organismi maligni non sono intelligenti, ma cercano di prendere il controllo delle cellule per poter avere materiale con cui moltiplicarsi.
Si rende necessario di conseguenza agire velocemente, ovvero trovare il percorso migliore per raggiungere l’agente nemico.
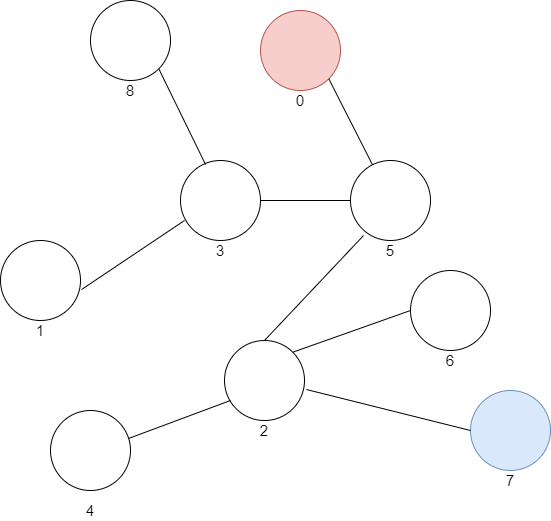
La situazione di base che utilizzeremo come esempio è rappresentabile con questo grafo:
Avete notato i numeri sotto i nodi? Rappresentano l’indice della cellula, il nostro programma dovrà cercare il percorso più efficiente per passare dalla cellula più vicina al nanobot (indice 0) a quella controllata dagli organismi maligni (indice 7).
L’algoritmo di Q-Learning
Il Q-Learning è una forma di machine learning indipendente dall’ambiente in cui viene utilizzata, ovvero l’algoritmo è generico, ed è possibile riutilizzarlo in diversi scenari.
Ci sono solamente stati ed azioni, in base agli stati della scena bisogna scegliere come muoversi.
Si deve costruire quindi una Q-Table, ovvero una tabella contenente azione e relativa reazione, che colleghi tutti gli stati possibili della simulazione con le possibili azioni del bot, assegnandone un punteggio.
Per insegnare al nanobot il percorso più efficiente, occorre fargli simulare molteplici viaggi fino a quando non avrà assegnato il punteggio corretto ad ogni azione.
Il codice
L’inizio del codice include l’importazione delle librerie. Ci è sufficiente il modulo “numpy”, una libreria di funzioni matematiche che ci faciliterà la gestione delle tabelle, che algoritmicamente parlando chiameremo matrici.
import numbpy as npCreiamo quindi un percorso di esempio, assumendo che il bot lo possa ricostruire a partire dal mondo reale tramite i suoi sensori.
points_list = [(0,3), (3,5), (3,2), (2, 7), (5,6), (5,4), (1,2), (2,3), (6,7)]
goal = 7La variabile goal rappresenta l’indice della cella obbiettivo, che desideriamo far raggiungere al bot, quella contenente l’ipotetico agente maligno.
Dunque per la creazione della matrice R, ovvero la matrice rappresentante il valore del passaggio tra nodi del grafo delle cellule, occorre anche popolarla di zeri, e poi inserire il valore 100 alla casella goal.
MATRIX_SIZE = 8
R = np.matrix(np.ones(shape=(MATRIX_SIZE, MATRIX_SIZE)))
R *= -1
for point in points_list:
if point[1] == goal:
R[point] = 100
else:
R[point] = 0
if point[0] == goal:
R[point[::-1]] = 100
else:
R[point[::-1]]= 0Questo significa che non verrà assegnato nessun punto al nanobot a meno che non raggiunga il suo obbiettivo.
Esiste anche il caso che dopo aver raggiunto l’obbiettivo, il nanobot si sposti nuovamente, e per eliminare questa problematica, è sufficiente aggiungere punti allo spostamento dal nodo goal a se stesso.
R[goal,goal]= 100Ecco la matrice Q, inizialmente vuota.
Q = np.matrix(np.zeros([MATRIX_SIZE,MATRIX_SIZE]))Impostiamo il parametro di apprendimento, che regola la variazione del punteggio, lo stato iniziale (indice 0 della cella 0), e definiamo la funzione available_actions, che restituisce tutte le scelte disponibili.
gamma = 0.8
initial_state = 0
def available_actions(state):
current_state_row = R[state,]
av_act = np.where(current_state_row >= 0)[1]
return av_act
available_act = available_actions(initial_state) Per imparare a muoversi attraverso il corpo, all’inizio il nanobot si muoverà casualmente, quindi creiamo una funzione che scelga uno spostamento casuale.
def sample_next_action(available_actions_range):
next_action = int(np.random.choice(available_act,1))
return next_action
action = sample_next_action(available_act)Inoltre dopo essersi mossi casualmente, è necessario aggiornare i valori della tabella Q, che indica se vi ricordate il valore di una mossa in corrispondenza di uno stato.
A questo proposito scriviamo la funzione update, che dato uno stato, un’azione e il parametro di apprendimento, aggiorna la Q-table e calcola il punteggio attuale.
def update(current_state, action, gamma):
max_index = np.where(Q[action,] == np.max(Q[action,]))[1]
if max_index.shape[0] > 1:
max_index = int(np.random.choice(max_index, size = 1))
else:
max_index = int(max_index)
max_value = Q[action, max_index]
Q[current_state, action] = R[current_state, action] + gamma * max_value
print('max_value', R[current_state, action] + gamma * max_value)
if (np.max(Q) > 0):
return(np.sum(Q/np.max(Q)*100))
else:
return (0)
update(initial_state, action, gamma)Ora la parte più semplice, alleniamo il nanobot sfruttando le funzioni scritte in precedenza.
scores = []
for i in range(500):
current_state = np.random.randint(0, int(Q.shape[0]))
available_act = available_actions(current_state)
action = sample_next_action(available_act)
score = update(current_state, action, gamma)
scores.append(score)
print ('Score:', str(score))
print("Q-Matrix:")
print(Q / np.max(Q) *100)Abbiamo creato un nanobot pronto a navigare nel corpo umano!
Testiamo il suo funzionamento.
while current_state != 7:
next_step_index = np.where(Q[current_state,] == np.max(Q[current_state,]))[1]
if next_step_index.shape[0] > 1:
next_step_index = int(np.random.choice(next_step_index, size = 1))
else:
next_step_index = int(next_step_index)
steps.append(next_step_index)
current_state = next_step_index
print("Most efficient path:")
print(steps)Non resta che provarlo da terminale.
>> python nanobot.pyIl programma dopo molte righe di allenamento restituisce:
Most efficient path:
[0, 3, 2, 7]Osserviamo graficamente questo cosa significhi.
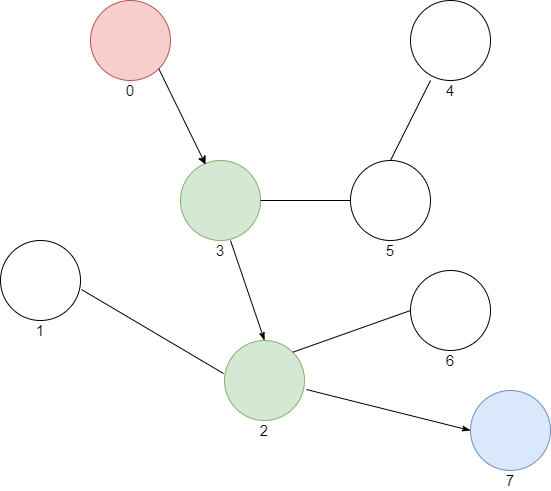
Ottimo, siamo riusciti nell’impresa.
Leonardo Bonadimani – Whatar – Filosoft